


1、C语言伪随机数生成基础
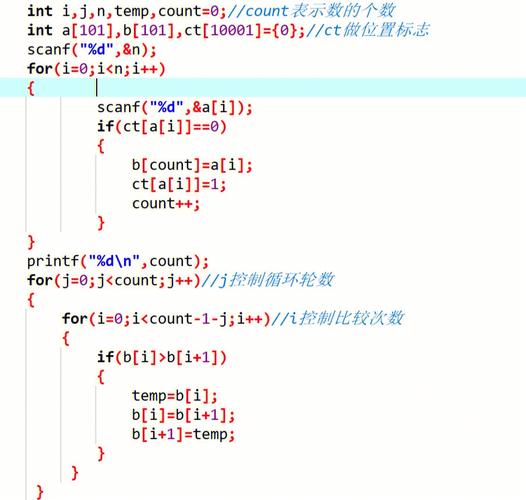

在C语言中,伪随机数的生成主要依赖于两个函数:srand()和rand(),这两个函数位于stdlib.h头文件中,srand()函数用于设置随机数生成器的种子(seed),而rand()函数则用于生成随机数。
使用系统时钟作为种子是常见做法,因为时钟值通常具有较高的随机性和变化性,通过这种方式,可以确保每次程序运行时生成的随机数序列都不同。
2、线性同余生成器原理
线性同余生成器是最常用的伪随机数生成算法之一,其工作原理基于线性同余方程:Xn+1 = (aXn + c) mod m,其中Xn是当前随机数,a、c和m是常数,a是乘数,c是增量,m是模数。
选择合适的a、c和m值对于生成高质量的伪随机数至关重要,这些参数的选取直接影响到随机数序列的周期长度和分布均匀性。
3、伪随机数的应用与重要性
伪随机数在计算机科学和程序设计中有广泛的应用,如游戏开发中的随机事件模拟、数据科学中的随机抽样、密码学中的加密算法以及仿真领域的各种模型。

高质量的伪随机数生成算法能够提供接近真实随机性的输出,这对于保证应用程序的安全性和可靠性非常重要。
4、高级随机数生成方法
除了线性同余生成器外,还有其他更复杂的随机数生成算法,如梅森旋转算法(Mersenne Twister)和斐波那契随机数生成器等,这些算法旨在解决线性同余生成器的一些局限性,如提高随机数的周期长度和改善统计特性。
这些高级算法通常具有更好的随机性和更长的周期,适用于对随机数质量要求更高的应用场景。
5、伪随机数的评估与测试
评估伪随机数的质量是一个复杂的过程,涉及到统计分析和经验测试,常用的测试包括频率测试、序列测试和运行测试等。
确保伪随机数生成器能够通过多种测试是其被广泛接受和应用的关键,这些测试帮助开发者了解生成器的可靠性和适用性。
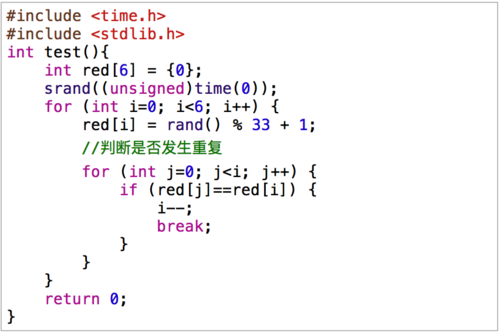
相关问答FAQs
Q1: 如何选择合适的随机数种子?
A1: 选择随机数种子应考虑其随机性和变化性,常用的种子来源包括系统时钟、进程ID或其他动态变化的系统参数,种子的选择直接影响到随机数序列的初始状态和整体随机性。
Q2: 为什么伪随机数不是真正的随机数?
A2: 伪随机数之所以不是真正的随机数,是因为它们由确定性的算法生成,尽管这些算法试图模仿真正的随机行为,但仍然是有规律可循的,真正的随机数应该是完全不可预测且没有规律的。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/735521.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复