

排序算法是计算机科学中基础且重要的部分,它关乎数据结构的处理效率与系统性能的优化,排序算法种类繁多,每种算法都有其独特的优势和适用场景,本文将详细比较各种常用排序算法的性能,包括它们的时间复杂度、空间复杂度及稳定性,并探讨各自的应用场景。
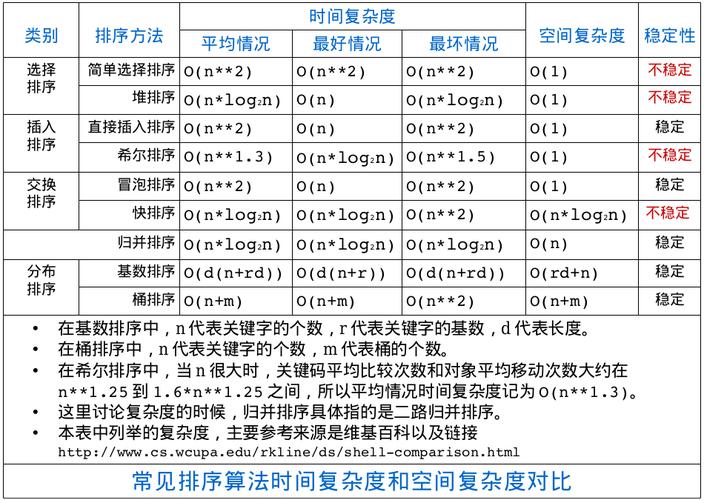

冒泡排序(Bubble Sort)是一种简单的排序算法,它重复地走访要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来,尽管这种算法实现简单,但由于其平均和最坏情况下的时间复杂度均为O(n²),在数据量大时效率较低。
选择排序(Selection Sort)的原理是每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完,该算法的时间复杂度同样为O(n²),适用于数据量较小的情况。
插入排序(Insertion Sort)构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,插入排序在实际应用中效率较高,尤其是对于小型文件。
希尔排序(Shell Sort)是插入排序的一种更高效的版本,通过比较相距一定间隔的元素来工作,随着算法的进行,这个间隔会逐渐减小,最终达到1,即直接的插入排序,希尔排序的时间复杂度依赖于所选取的增量序列,但通常比O(n²)要好。
归并排序(Merge Sort)采用分治法策略,将数组分成两半,分别对它们进行排序,然后将结果合并,该算法的时间复杂度为O(nlogn),是稳定的排序算法,并且可以用于外部排序。
快速排序(Quick Sort)也是使用分治策略,选择一个基准元素,通过一遍排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据要小,然后再递归排序这两部分,它的平均时间复杂度为O(nlogn),但是在最坏的情况下可以达到O(n²),快速排序通常比其他O(nlogn)算法更快,因为它的内部循环可以更方便地实现。
堆排序(Heap Sort)利用了二叉堆的特性进行排序,时间复杂度为O(nlogn),计数排序(Counting Sort)和桶排序(Bucket Sort)是非比较类排序算法,适用于要排序的关键字是离散的情况,基数排序(Radix Sort)则是按照低位先排序,再按照高位排序的原则进行的非比较类排序算法。
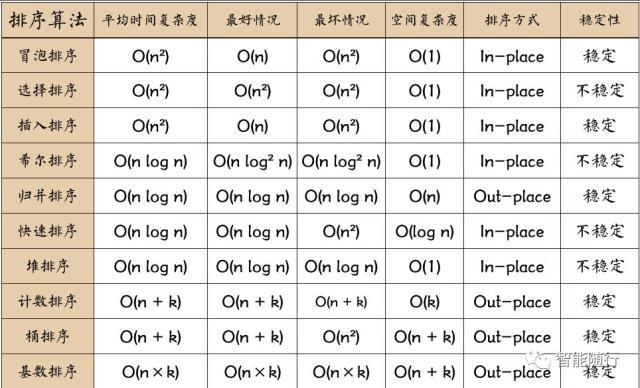
各种排序算法的稳定性也是一个重要考量点,稳定性意味着相同值的元素在排序前后保持它们原有的相对位置,归并排序和冒泡排序是稳定的,而快速排序和希尔排序则不是。
总的来看,选择合适的排序算法需要考虑具体应用场景的需求,对于大量数据的排序,通常推荐使用快速排序或归并排序;而对于小量数据或者几乎已排序的数据,插入排序可能更为高效,了解各算法的特性和适用场景,有助于在实际应用中做出更合理的决策。
相关问答FAQs
什么是稳定性在排序算法中的重要性?
稳定性在排序算法中指的是,若两个元素具有相等的键值,则它们在排序后的相对位置应保持不变,稳定性对于多次排序非常有用,特别是在多级排序中,当按年份和月份两级信息对文件进行排序时,稳定性确保了同年不同月的文件不会改变它们的原始顺序。
如何选择合适的排序算法?
选择合适的排序算法主要取决于三个因素:数据量的大小、最好和最坏情况的时间复杂度以及空间复杂度,对于大数据量,应选择快速排序或归并排序;对于小数据量或基本有序的数据,插入排序可能更优,同时考虑算法的稳定性,根据实际需求选择稳定或非稳定算法。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/735123.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复