


Kettle是一款开源的ETL(Extract, Transform, Load)工具,由Pentaho Data Integration发展而来,纯Java编写的特点使其具有跨平台性,能在Windows、Linux、Unix等多个操作系统上运行,本指南将详细介绍如何利用Kettle进行数据的导入操作,旨在帮助用户高效完成数据抽取、转换和加载的任务。

环境准备
1、系统要求:Kettle是基于Java的应用,因此需要预先安装Java运行环境,具体步骤如下:
右击“我的电脑”属性高级系统设置环境变量系统变量新建
变量名:JAVA_HOME
变量值: JDK安装目录
2、下载与解压:
访问Kettle官方网站下载最新版的Kettle工具。
下载完成后,解压缩到任意目录。
3、首次运行:
进入解压后的目录,找到spoon.bat(Windows系统)或spoon.sh(Linux/Unix系统),双击运行。
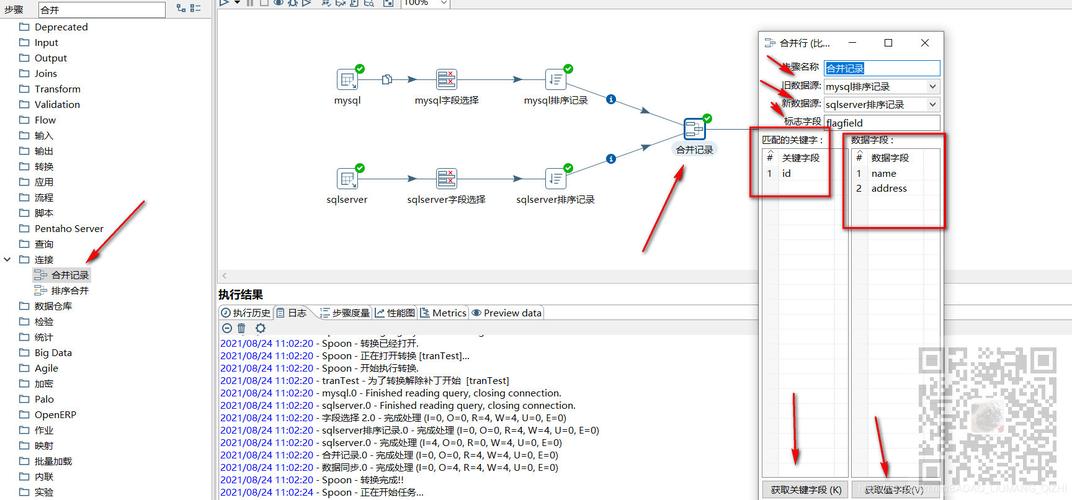
资源库连接
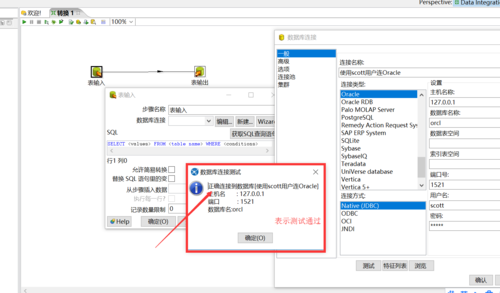
1、数据库连接配置:
在Kettle中,首先需要配置数据库连接,进入“工具”>“资源库配置”,选择资源库类型如MySQL、Oracle等。
录入资源库信息,包括主机名、端口号、数据库名、用户名和密码。
测试连接,确保信息无误后保存。
2、资源库登录:
使用配置好的账号信息登录资源库,这将允许您保存和管理您的ETL任务。
方案开发
1、新建转换:
在Kettle中,每一个数据处理流程称为一个“转换”,点击“新建”按钮,输入转换名称并选择归属文件夹。
2、建立表输入:
从“输入”类组件中拖拽“表输入”到流程设计区,双击配置数据源,选择之前配置好的数据库连接,并选择需要导入的数据表。
3、步骤链接:
根据需求添加必要的“转换”组件,如“排序”、“去重”等,通过拖拽方式链接各步骤,形成完整的数据处理流程。
4、数据输出:
从“输出”类组件中选择“表输出”,配置目标数据库信息,并将之链接到流程的最后一步。
5、执行与调试:
在工具栏点击“运行”按钮执行转换,通过日志信息检查流程是否按预期执行,必要时对问题步骤进行调试。
数据导入示例
1、DEMO:
假设需要将本地CSV文件数据导入到数据库表中,配置CSV文件输入,然后根据需要进行数据加工处理,最后输出到数据库。
2、具体操作:
选择“文本文件输入”组件配置CSV文件路径,“表格输出”组件配置目标数据库表及字段映射。
3、执行结果:
运行转换,查看日志确认数据正确导入,此时数据库表中应已成功接收到CSV文件中的数据。
通过上述步骤,用户可以完成从不同数据源到各种数据库的数据导入工作,实现数据的有效整合和分析,作为开源强大的ETL工具,Kettle为数据处理提供了灵活、高效的解决方案,希望本教程能帮助用户掌握使用Kettle进行数据导入的方法,进一步提升数据处理的效率和质量。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/734893.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复