


在计算机科学领域中,排序算法是数据处理的基础,也是算法学习路径上的重要一环,本文将深入探讨多种常见的排序算法,对它们进行分类,并分析各自的特点和使用场景,具体如下:


1、比较类排序算法
快速排序:快速排序是一种分而治之的排序算法,在平均情况下,它的时间复杂度是O(nlogn),最坏情况下是O(n^2),它的工作原理是选择一个基准元素,然后将数组分为两个子数组,一个包含小于基准的元素,另一个包含大于或等于基准的元素,然后递归地排序这两个子数组。
归并排序:归并排序也是一种使用分而治之策略的算法,无论最好、最坏还是平均情况,其时间复杂度均为O(nlogn),归并排序的核心思想是将数组分成两半,分别对这两半递归地应用排序,然后将两个已排序的半部分合并成一个有序数组。
堆排序:堆排序利用堆数据结构的特性,能保持O(nlogn)的时间性能,堆排序首先将输入的无序数组构建成最大堆,然后通过不断移除堆顶元素,并调整堆的结构来完成排序。
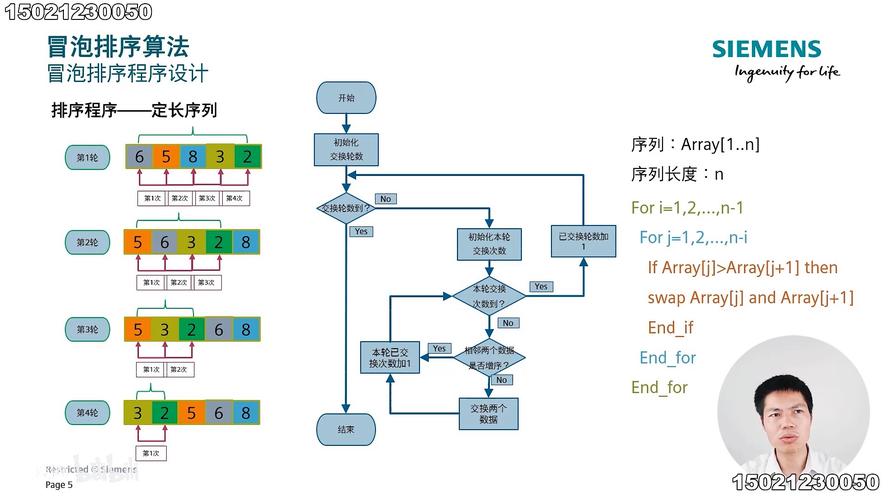
冒泡排序:冒泡排序是最简单的排序算法之一,它重复地走访要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来,冒泡排序的最坏和平均时间复杂度均为O(n^2)。
2、非比较类排序算法
计数排序:计数排序是一种线性时间排序算法,适合用来排序小范围的整数,计数排序的基本思想是对每一个输入元素x,确定小于x的元素个数,然后在输出数组的对应位置放置x。
基数排序:基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集,以此类推,直到最高位,有时候也用于对浮点数或者字符串进行排序,这时候把整数的位数换成了浮点数的精度或者字符串的长度。
桶排序:桶排序也属于分布排序的一种,工作原理是将数组分到有限数量的桶里,每个桶再个别排序,可能再使用其他排序算法或是以递归方式继续使用桶排序进行排序。
3、插入排序类
直接插入排序:直接插入排序将一个记录插入到已经排序好的有序表中,从而得到一个新的、记录数增1的有序表,直接插入排序的最坏和平均时间复杂度均为O(n^2)。
希尔排序:希尔排序是直接插入排序的一种改进版本,通过设置跳跃间隔序列来加快排序速度,最终收敛到直接插入排序。
4、选择排序类
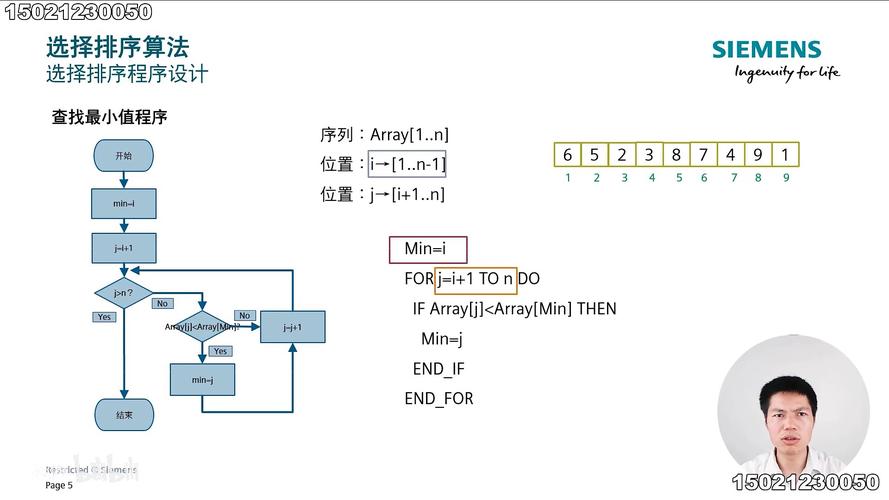
简单选择排序:简单选择排序的基本思想是在第一轮中选择剩余元素中的最小值,与当前位置元素交换,第二轮中选择[2, n],第三轮选择[3, n],依次类推。
堆排序:堆排序可以看作是选择排序的变种,借助堆数据结构的特性,能够以更有效的方式找出最小(或最大)元素。
5、归并排序类
归并排序:归并排序不仅适用于常规的数据排序,还能用于外部排序,如分布式系统中的多路归并。
6、交换排序类
冒泡排序:冒泡排序每次遍历都会将最大的元素“冒泡”到正确的位置。
快速排序:快速排序可以看作是冒泡排序的优化版本,通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,然后分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
这些排序算法各有优劣,选择合适的排序算法需要根据具体问题的场景来决定,比如数据量大小、数据的初始状态(是否接近有序)以及内存使用限制等,理解各种排序算法的原理和特性,对于编写高效的代码至关重要。
FAQs
1. 什么是稳定排序算法?
稳定的排序算法能保证具有相同键值的元素在排序前后保持原有的相对顺序不变,插入排序、归并排序和冒泡排序都是稳定的排序算法。
2. 如何选择最适合的排序算法?
选择最适合的排序算法时,需要考虑数据的规模、数据是否近乎有序、内存使用限制以及是否需要稳定排序等因素,对于小规模数据可以使用插入排序或选择排序,大规模数据则更适宜使用快速排序或归并排序;在数据近乎有序的情况下,插入排序会有较好的表现;如果需要稳定排序,则应选择归并排序等稳定的算法。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/734420.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复