


在MapReduce编程模型中,查看结果是一个关键步骤,它允许用户确认他们的程序是否按预期执行并产生了正确的输出,MapReduce作业的结果通常存储在分布式文件系统(如HDFS)上,可以通过多种方式进行查看。

查看MapReduce结果
使用命令行工具
1、Hadoop File System (HDFS) Commands:
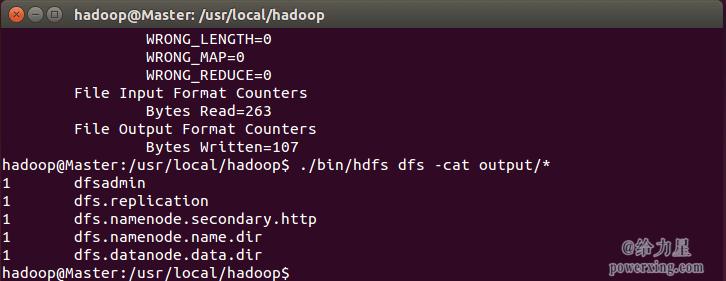
使用hadoop fs cat <path>命令可以查看HDFS上文件的内容,如果结果存储在/output目录下,可以通过运行hadoop fs cat /output/partr00000查看第一个结果文件的内容。
使用hadoop fs ls <path>可以查看指定路径下的文件列表。
2、Hadoop Job Commands:
使用hadoop job list all可以查看所有提交的作业。
使用hadoop job status job_id可以获取特定作业的状态信息。
使用hadoop job counter job_id org.apache.hadoop.mapreduce.TaskCounter可以查看作业的计数器信息。
使用Web界面
1、ResourceManager Web UI:
访问ResourceManager Web UI(通常是http://<resourcemanagerhost>:8088/)可以查看正在运行和已完成的作业列表。
点击特定作业可以查看详细的作业信息,包括作业配置、运行状态、完成的任务等。
2、JobHistory Web UI:
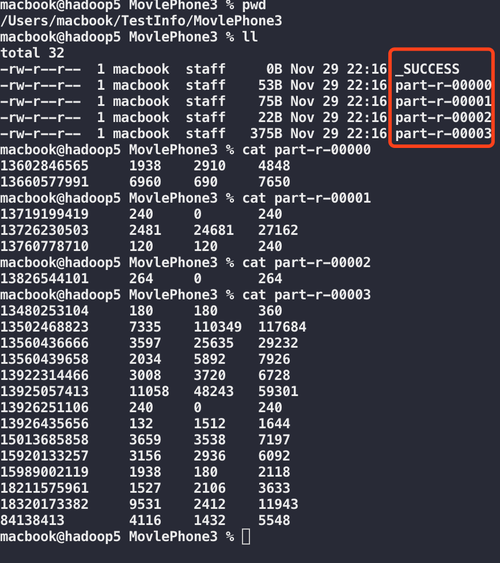
访问JobHistory Web UI(通常是http://<jobhistoryhost>:19888/)可以查看历史作业的信息。
可以查看每个作业的详细日志,了解任务执行的细节,包括mapper和reducer的输出。
使用编程方式
1、Java API:
使用Hadoop Java API可以直接编写代码来获取作业结果,可以使用FileSystem类来读取HDFS上的文件内容。
可以使用Job类来获取作业的状态和统计信息。
2、其他语言SDK:
如果使用的是其他编程语言,如Python、Scala或PHP,可以使用相应的Hadoop SDK来与MapReduce作业交互。
结果解析
文本格式: 如果结果是纯文本格式,可以直接查看。
SequenceFile: 如果结果是SequenceFile格式,需要使用Hadoop的SequenceFile API来读取。
自定义格式: 如果使用了自定义的输出格式,需要按照该格式的规范来解析结果。
结果验证
比较预期与实际输出: 根据业务逻辑,比较预期的结果和实际的输出是否一致。
数据完整性检查: 检查输出数据的完整性,确保没有数据丢失或错误。
性能评估: 根据作业的运行时间、处理的数据量等指标评估性能。
结果优化
调整参数: 根据作业的运行情况调整MapReduce的配置参数,如内存大小、并发任务数等。
代码优化: 根据结果分析可能的性能瓶颈,优化MapReduce代码。
数据预处理: 对输入数据进行预处理,以提高作业的处理效率。
相关问答FAQs
Q1: MapReduce作业完成后,如何快速定位到失败的原因?
A1: 可以通过以下几种方式定位失败原因:
查看作业日志:通过Hadoop Job History Web UI查看作业的详细日志,通常会包含错误信息和异常堆栈。
分析计数器信息:使用hadoop job counter命令查看作业的计数器信息,如失败的任务数、重试次数等。
检查配置文件:检查作业的配置文件是否正确设置了必要的参数,如输入输出路径、资源需求等。
Q2: 如果MapReduce作业的结果不符合预期,应该如何排查问题?
A2: 以下是排查问题的步骤:
验证输入数据:确保输入数据是正确的,并且符合作业的预期格式。
审查代码逻辑:仔细检查Map和Reduce函数的逻辑,确保它们能够正确处理数据并生成预期的输出。
测试小规模数据集:使用小规模的数据集进行测试,以便更快地发现问题所在。
使用调试工具:如果可能,使用调试工具逐步执行代码,以找出潜在的逻辑错误或数据处理问题。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/734312.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复