


随着数据量的飞速增长,传统的数据处理工具已经无法满足需求,Hadoop作为一个开源框架,凭借其分布式存储和处理大数据的能力,成为了解决这一难题的关键工具,Hadoop的核心组件HDFS和MapReduce分别承担了数据存储和处理的任务,本文旨在全面介绍Hadoop在大数据处理中的应用,特别是SQL on Hadoop技术,以及它们在现代数据处理中的重要性。
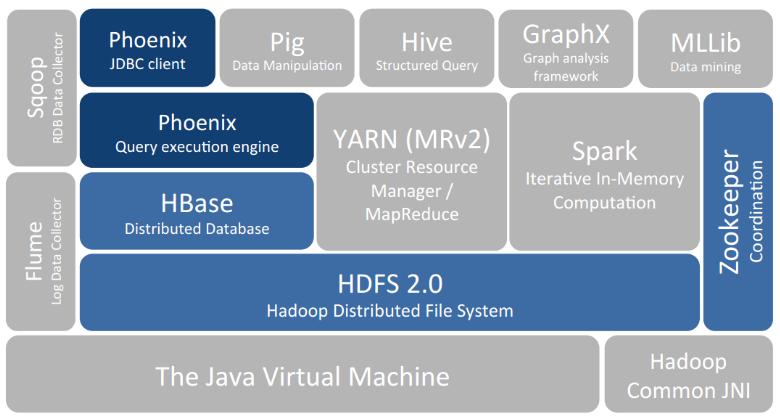

了解Hadoop的基本架构是理解其工作原理的基础,Hadoop主要由两大部分构成:HDFS(Hadoop Distributed File System)和MapReduce,HDFS是一个分布式文件系统,设计用于在商用硬件上存放超大量数据,它通过将数据块分布在多台机器上,实现数据的高容错性和高吞吐量,MapReduce则是一种编程模型,用于大规模数据集的并行运算,它将任务分为两个阶段:Map阶段和Reduce阶段,从而实现高效的数据处理。
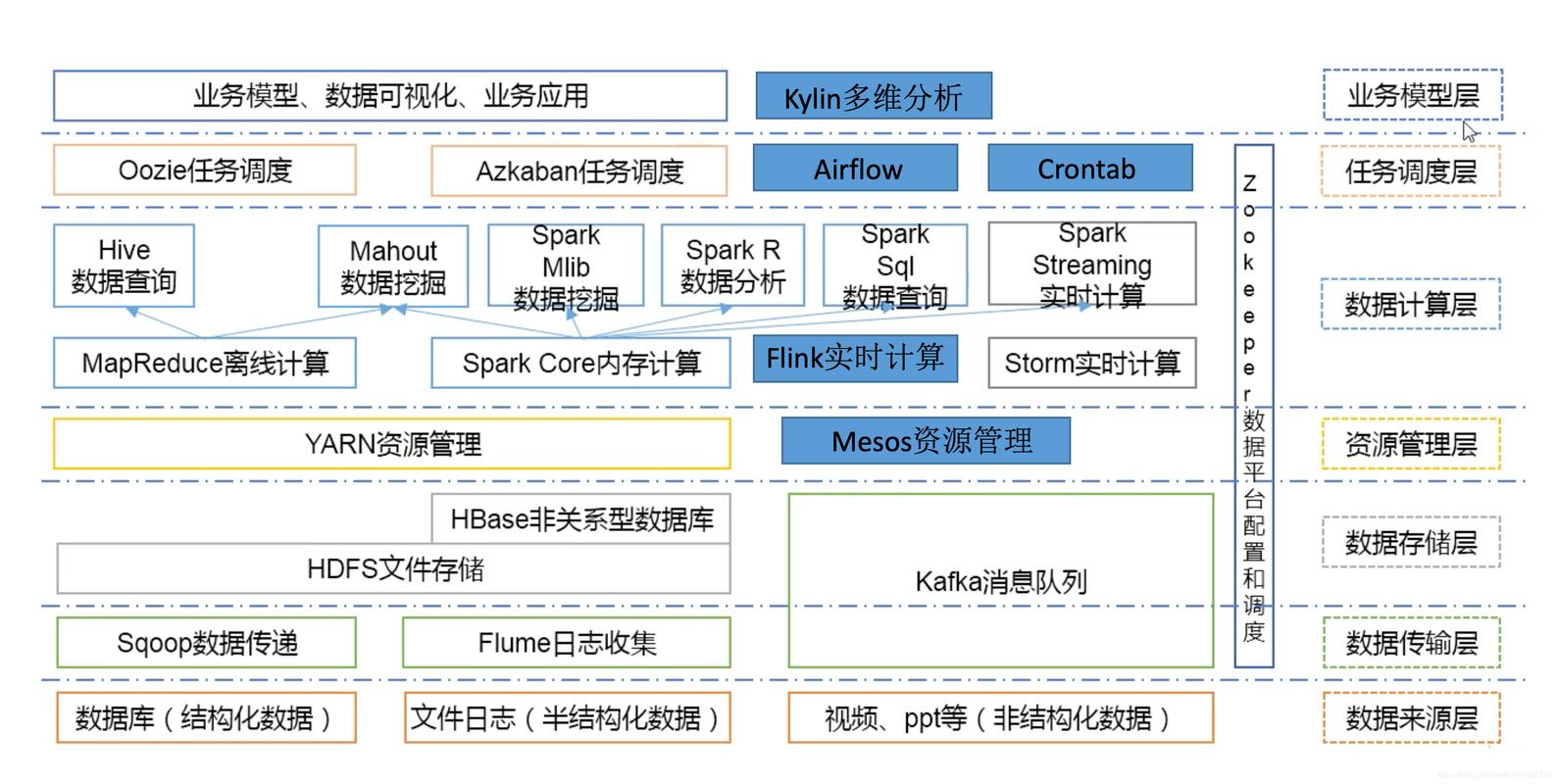
接下来是对SQL on Hadoop的理解,SQL on Hadoop指的是在Hadoop平台上执行SQL查询的技术,这使得用户可以使用熟悉的SQL语言来查询存储在HDFS中的数据,这种技术大大简化了大数据分析的过程,使得即使是没有专业编程技能的用户也能轻松进行数据分析,根据查询时延的不同,SQL on Hadoop可分为三类:batch SQL、interactive SQL和operational SQL,这三种类型分别针对不同的查询需求,从批量处理到实时交互,满足各种不同的业务需求。
而在实际应用中,选择合适的大数据平台至关重要,虽然Hadoop提供了强大的数据处理能力,但在一些特定的场景下,其他框架如Spark和Flink可能会更加适合,Spark在迭代算法和实时数据处理方面表现更佳,而Flink则在流处理和事件驱动的应用中有更出色的表现,根据具体的业务需求和数据特性选择合适的框架,对于确保数据处理效率和性能至关重要。
对于初学者而言,搭建一个Hadoop环境并开始使用SQL on Hadoop可能是一项挑战,幸运的是,有许多资源和教程可供参考,帮助新手逐步建立起自己的Hadoop集群,并通过实践学习如何利用SQL on Hadoop来进行数据分析,这不仅涉及软件的安装配置,还包括对Hadoop生态系统的深入理解,比如YARN(Yet Another Resource Negotiator)等其他组件的使用和管理。
在深入探讨了Hadoop及其SQL on Hadoop技术后,值得进一步讨论一些相关的实用问题,数据的安全性、隐私保护以及处理效率优化等都是使用Hadoop时需要考虑的重要方面,对于不同规模的企业,如何选择合适的Hadoop部署模式(如公有云、私有云或混合云)也是一个值得深思的问题。
相关问答FAQs
如何在Hadoop上实施SQL查询?
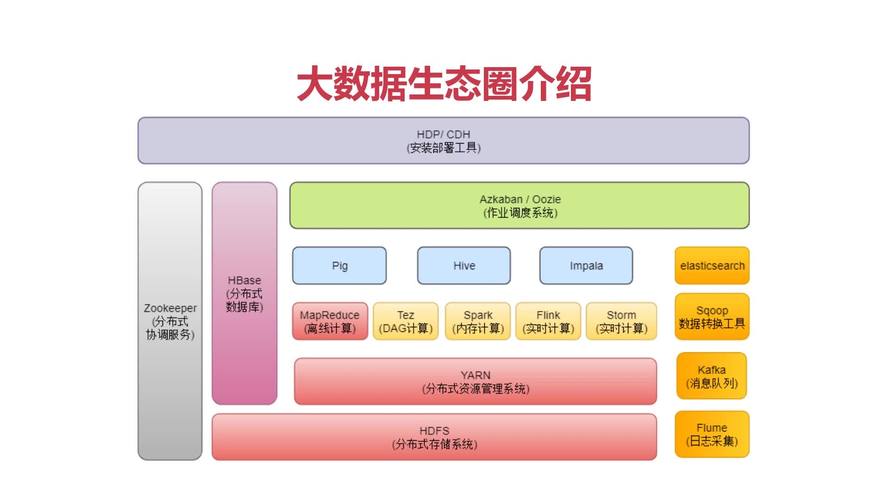
要在Hadoop上实施SQL查询,首先需要设置合适的SQL on Hadoop系统,如Apache Hive或Apache Impala等,这些系统允许用户通过提交SQL语句来查询存储在HDFS中的数据,具体步骤包括配置系统环境,加载数据至HDFS,然后使用SQL客户端提交查询。
Hadoop在数据处理中的优势是什么?
Hadoop的最大优势在于其能够处理和分析超大规模的数据集,通过分布式存储和并行处理,Hadoop能够高效地处理PB级别的数据,它的成本效益也非常高,因为它可以在普通的硬件上运行,无需昂贵的专用硬件支持。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/734232.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复