


【词袋模型 mapreduce_MapReduce】

在自然语言处理(NLP)和文本分析的领域里,词袋模型(Bag of Words Model)扮演着基础的角色,它是一种简单且广泛使用的文本表示方法,将文本简化为单词的集合,从而方便计算机进行进一步的处理,MapReduce作为一种编程模型,主要用于大规模数据集(大于1TB)的并行运算,它通过把作业分成两个阶段——Map阶段和Reduce阶段来简化计算过程。
词袋模型:从理论到实践
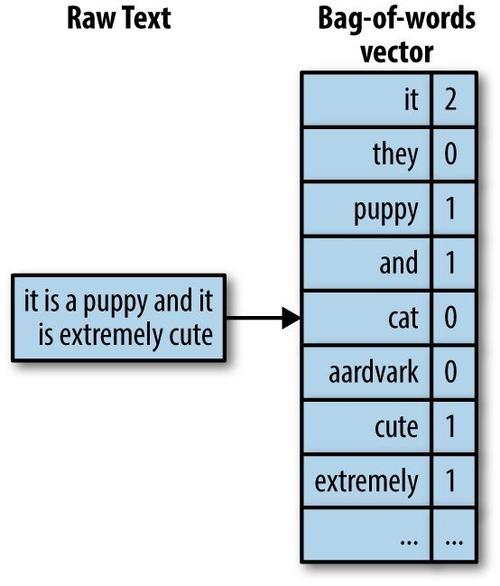
词袋模型的核心思想是忽略文本中单词的顺序和语法结构,只关注单词的出现频率,这种模型将文本转化为一个向量,其中的每个元素对应于字典中的一个单词,而元素的值则代表了该单词在文本中出现的次数或频率。
构建词袋模型的基本步骤通常包括文本清洗、分词、生成词汇表、计数和权重赋值等环节,需要对原始文本数据进行预处理,包括去除标点符号、转换为小写、移除停用词等步骤,以减少噪声并标准化文本,通过分词将文本拆分成单词,根据所有文档中出现的独特单词建立一个词汇表,对于每个文档,统计词汇表中每个单词的出现次数,生成一个代表该文档的向量,有时候为了反映单词的重要性,会对单词的出现次数进行加权处理。
MapReduce:分布式计算的基石
MapReduce由两个主要部分组成:Map函数和Reduce函数,在Map阶段,输入数据被分成多个数据块,每个数据块分别由不同的Map任务处理,生成一组中间键值对,在Reduce阶段,这些中间键值对根据键进行合并,并由Reduce任务处理得到最终的结果。
一个典型的应用场景是WordCount程序,它统计文件中每个单词出现的次数,在这个例子中,Map函数读取文件的一部分内容,并为每个单词生成一个键值对,其中键是单词本身,值是该单词出现的次数,Reduce函数则负责将所有相同的键(即同一个单词)的值(出现次数)相加,得出总的出现次数。
结合使用词袋模型与MapReduce
在处理大规模文本数据时,可以将词袋模型的构建过程与MapReduce框架相结合,Map函数可以用于生成每个文档的词袋模型,而Reduce函数则可以对这些模型进行汇总,得出全局的词袋模型,这种方法不仅可以提高处理速度,而且能够有效地处理海量数据。
词袋模型的局限性
尽管词袋模型简单易用,但它也有明显的局限性,由于忽略了词语间的顺序关系,使得语义信息丢失严重,当词汇表非常大时,生成的向量也会非常稀疏,这给计算带来了挑战。
常见问题解答
Q1: 如何优化词袋模型以减少维度灾难?
A1: 可以通过特征选择方法如信息增益、卡方检验等来选取最有影响力的特征;或者使用词嵌入(Word Embeddings)方法如Word2Vec或GloVe来降低维度。
Q2: MapReduce是否适合所有类型的大数据处理?
A2: 虽然MapReduce非常适合批量处理大量数据,但对于需要实时处理的场景则不太适合,此时可以考虑使用其他框架,例如Apache Spark。
词袋模型和MapReduce在自然语言处理和大数据分析领域内发挥着重要作用,它们各自的特点和优势使得它们成为处理大规模文本数据不可或缺的工具,随着技术的发展,新的模型和方法不断涌现,人们也在不断探索如何克服现有方法的局限,以期达到更高的数据处理效率和更好的分析结果。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/733685.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复