

【词转化为词向量】

词向量,作为一种重要的文本表示方法,在自然语言处理(NLP)领域扮演着核心角色,词向量技术能够将语言中的词汇映射到数学上可操作的向量空间,使得计算机能够通过这些向量来理解、处理和生成语言数据,本文旨在全面介绍词转化为词向量的过程,包括其理论基础、主要技术、优缺点以及应用场景。
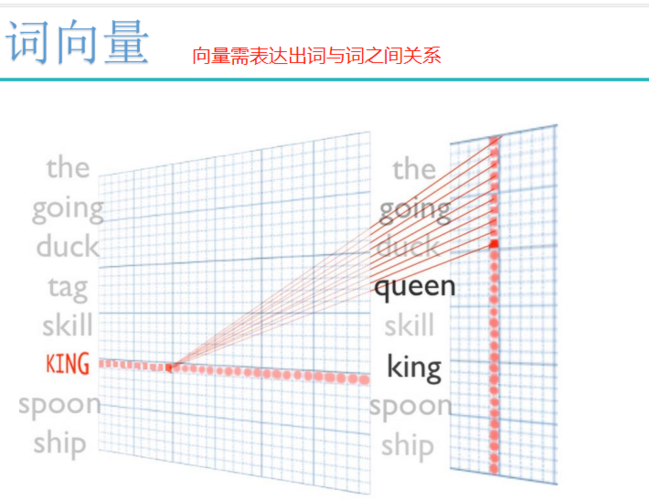
了解什么是词向量至关重要,词向量是一种将单词表达为实数域中的向量的技术,这些向量捕捉了单词之间的语义关系,在众多词向量模型中,Word2Vec是最为广泛使用的一种,Word2Vec,由Google在2013年开发,通过训练可以把语言中的词映射到向量空间中,而在这个空间内,位置相近的词意味着它们具有相似的语义,Word2Vec主要有两大架构:连续词袋模型(CBOW)和跳跃式模型(SkipGram),CBOW模型通过上下文来推断当前词,而SkipGram模型则是从当前词预测其上下文。
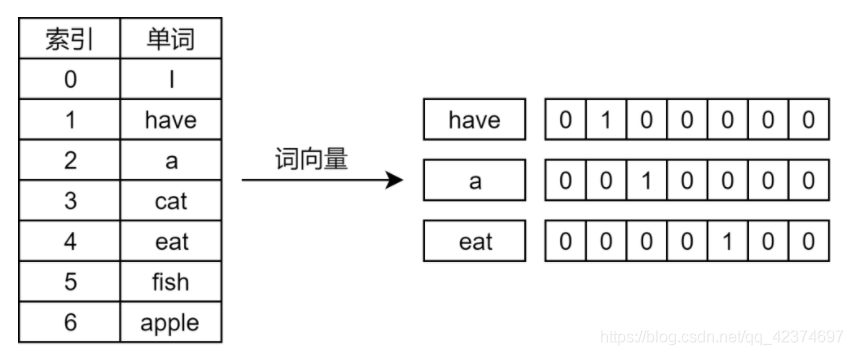
让我们探讨一下OneHot编码,这是另一种将词转换为向量的方式,OneHot编码是一种简单的词到向量空间的映射技术,它将每个词视为一个特征,并分配一个高维度的向量,如果语料库中有V个唯一的词,则每个词都会被映射到一个V维的向量中,在该向量中,仅有一个元素的值为1,其他均为0,这种方法虽然简单直观,但在处理大规模文本数据时会引发维度灾难,且无法捕捉词与词之间的语义关系。
传统的OneHot编码存在明显的缺点,如维度过高和无法体现词语间的关系,相比之下,Word2Vec及类似的词嵌入技术,如GloVe和FastText,通过训练模型来学习词语的分布式表示,有效解决了这些问题,这些模型可以将词汇映射到低维空间,同时保留词语的语义信息,在Word2Vec模型中,训练过程涉及大量的文本数据和复杂的数学运算,但最终得到的词向量能够较好地反映词语间的实际相似度。
为了更深入地理解词向量的生成过程,我们可以通过一个简化的例子来看CBOW模型是如何工作的,假设我们有一个句子“我喜欢吃苹果”,在这个句子中,“苹果”是输入词,“我”、“喜欢”和“吃”构成了它的上下文,CBOW模型会尝试根据这些上下文词来预测中心词“苹果”,在这个过程中,模型会调整各单词对应的向量,使得从上下文词的向量可以尽可能地重构或预测出中心词的向量,经过大量此类训练后,语义上相近的词在向量空间中的位置也会比较接近。
进入归纳和一些横向对比,除了Word2Vec以外,其他的词嵌入技术如GloVe和FastText也各有千秋,GloVe模型通过统计全局词词共现频率来生成词向量,而FastText则是对Word2Vec的一种扩展,支持词片段信息,能更好处理形态丰富的语言,每种技术都有其独特的优势和适用场景,选择哪一种往往取决于具体的任务需求和可用资源。
相关问答FAQs:
Q1: 使用Word2Vec有什么注意事项?
A1: 使用Word2Vec时需注意:确保有足够的训练数据以覆盖语言的多样性;合理选择向量的维度,以平衡计算效率和模型表现;以及仔细选择窗口大小等超参数来优化模型性能。
Q2: Word2Vec与其他词嵌入技术相比有何优劣?
A2: Word2Vec的主要优点是能够捕捉丰富的语义信息和灵活的模型架构选择,它可能不如GloVe在保持全局词共现结构方面表现出色,也不如FastText在处理形态丰富语言上高效,选择合适的词嵌入技术需要考虑具体的应用需求和数据集特性。
从理论到实践,词转化为词向量的技术不断演进,极大地推动了NLP领域的发展,尽管面临挑战,但这些技术已经并将继续在多个领域展示其强大的功能和潜力。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/733179.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

发表回复