


KL散度(KullbackLeibler Divergence)是衡量两个概率分布差异的指标,常用于机器学习和信息论。在Python中,可以使用
scipy.stats库中的函数实现KL散度的计算。集群指标用于评估聚类算法的性能,而维度则表示数据的复杂性。KL散度(KullbackLeibler Divergence)是一种衡量两个概率分布之间差异的方法,它衡量的是,当我们使用一个概率分布来近似另一个概率分布时,我们需要改变多少信息量,KL散度的值越大,两个概率分布之间的差异就越大。


(图片来源网络,侵删)
在Python中,我们可以使用SciPy库中的entropy函数来计算KL散度,以下是一个简单的例子:
from scipy.special import kl_div
import numpy as np
定义两个概率分布
p = np.array([0.1, 0.2, 0.7])
q = np.array([0.2, 0.3, 0.5])
计算KL散度
kl_divergence = kl_div(p, q)
print("KL散度:", kl_divergence) 在这个例子中,我们定义了两个概率分布p和q,然后使用kl_div函数计算它们之间的KL散度。
集群指标(Clustering Index)是一种评估聚类效果的指标,它可以帮助我们了解聚类结果的质量,常见的集群指标有轮廓系数(Silhouette Coefficient)和CalinskiHarabasz指数等。
轮廓系数是衡量聚类效果的一个指标,它的值介于1和1之间,轮廓系数越接近1,表示聚类效果越好;越接近1,表示聚类效果越差,轮廓系数的计算公式如下:
from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans
假设我们已经有了数据X和聚类标签labels
X = ...
labels = ...
使用KMeans进行聚类
kmeans = KMeans(n_clusters=3).fit(X)
计算轮廓系数
silhouette_coefficient = silhouette_score(X, labels)
print("轮廓系数:", silhouette_coefficient) CalinskiHarabasz指数是一种基于聚类内方差和聚类间方差的比值的指标,其值越大,聚类效果越好,计算公式如下:
from sklearn.metrics import calinski_harabasz_score
计算CalinskiHarabasz指数
calinski_harabasz_index = calinski_harabasz_score(X, labels)
print("CalinskiHarabasz指数:", calinski_harabasz_index) 这些指标可以帮助我们评估聚类算法的效果,并选择最佳的聚类数量。
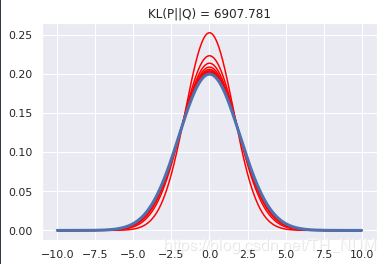
(图片来源网络,侵删)
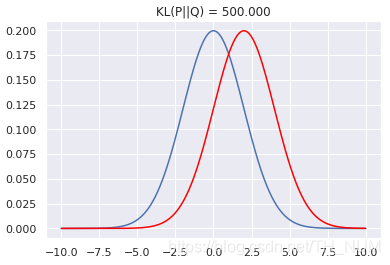
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/733014.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复