


在数据库管理中,分区是一种优化数据存储和管理的技术,通过将大表分割成多个较小的部分,可以提高查询效率,简化数据管理,并提升整体的系统性能,时间分区是按时间范围将数据分布在不同的分区中,这有助于处理时间序列数据,下面详细介绍创建时间分区的存储过程及其实现方式:
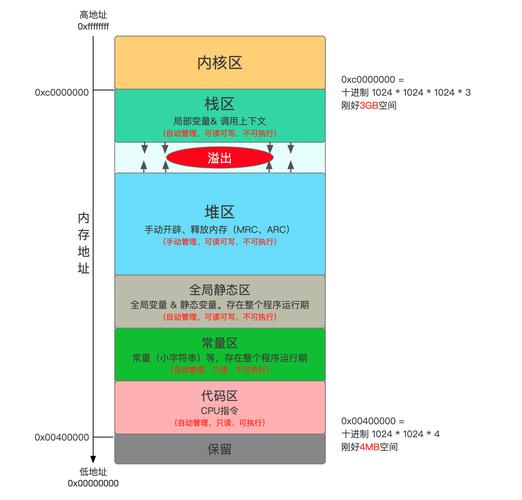

存储过程创建时间分区的基本步骤
1、确定分区键和分区范围
选择分区键:通常选取时间列作为分区键,如日期、年份或月份。
定义分区范围:根据业务需求设定分区的时间范围,例如每年一个分区或每月一个分区。
2、设计分区策略
固定时间范围分区:每个分区覆盖固定的时间范围,如每月一个分区。
动态时间范围分区:根据现有数据自动生成新的分区,新分区的范围基于最新数据的时间戳。
3、创建存储过程
自动化操作:编写存储过程以自动化新分区的创建,减少手动干预。
异常处理:在存储过程中加入异常处理逻辑,确保在遇到意外情况时能够安全地回滚或报告错误。
4、调度和监控
定时执行:使用数据库的任务调度功能(如MySQL的Event Scheduler)定期执行存储过程。
监控状态:监控分区创建的状态,确保存储过程正确执行,并及时处理可能出现的问题。
5、性能优化
索引优化:为分区表的分区键创建索引,提高查询速度。
查询优化:利用分区裁剪(partition pruning)优化查询,仅访问必要的分区。
6、维护与管理
合并和分裂:根据需要对分区进行合并或分裂,以适应数据量的变化。
数据归档:定期将旧分区的数据归档到其他存储介质,以释放空间和优化性能。
实现示例
1、创建存储过程
定义参数:存储过程接受如模式名、表名和时间范围等参数。
编写逻辑:编写SQL命令来检查是否存在分区,如果不存在则创建新分区。
2、执行存储过程
手动执行:在需要时手动调用存储过程来创建新分区。
自动执行:设置定期执行计划,使存储过程在特定时间自动运行。
3、性能考量
查询性能:分析分区对查询性能的影响,确保分区策略符合性能目标。
存储开销:评估分区对存储开销的影响,包括索引和数据冗余。
4、监控与调整
监控工具:使用数据库提供的监控工具跟踪分区的使用情况。
调整策略:根据实际使用情况调整分区策略,如改变分区的时间范围或数量。
相关操作和注意事项
确保在执行存储过程之前备份数据,以防止数据丢失。
测试存储过程在生产环境之前在开发或测试环境中的行为。
考虑不同数据库版本间的差异,确保存储过程的兼容性。
通过以上步骤,可以高效地实现时间分区的存储过程,从而优化数据库的性能和管理。
FAQs
如何在已存在的表上应用时间分区?
对于已经存在的表,可以通过修改表结构的方式来添加分区,需要确定合适的分区键和分区类型(如RANGE或LIST),然后使用ALTER TABLE语句添加分区定义,如果有一个未分区的日志表,可以将其转换为按年分区的表,以优化查询和管理。
如何处理跨分区查询的性能问题?
跨分区查询可能会影响性能,因为需要联合多个分区的数据,为了提高查询效率,可以考虑以下方法:使用分区裁剪来减少查询涉及的分区;为经常一起查询的分区键建立全局索引;或者重新设计分区策略,以减少跨分区查询的需要。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/732946.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复