


在现代软件开发中,数据库设计是构建任何数据驱动应用程序的基础和核心,一个良好的数据库设计不仅能够提高数据检索的效率,还能确保数据的完整性和系统的可扩展性,特别是在处理大数据量的应用场景下,合理的数据库对象设计显得尤为重要,本文将深入探讨大数据量数据库的设计要点,包括数据库结构设计、表的分区策略以及性能优化等方面。
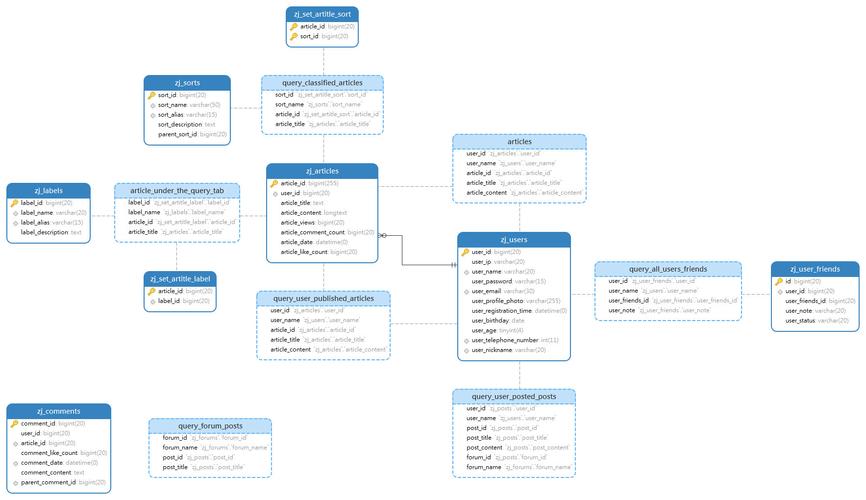

数据库结构设计是确保系统高效运行的关键,在系统分析和设计阶段,开发者往往容易被功能的实现所吸引,忽视了性能的重要性,如搜索结果显示,一个合理的数据库模型设计可以显著降低客户端和服务端的编程和维护难度,同时提升系统的实际运行性能,在系统实施之前,完备的数据库模型设计是必不可少的,这包括合理规划数据表和索引,选择适合的数据类型,以及考虑未来可能的数据扩展需求。
对于大数据量的情况,表的分区化是一种常见且有效的优化策略,当一个表的数据量超过500万时,应考虑将其设计为分区表;而数据量超过5000万时,则可能需要数据库管理员(DBA)的参与进行更精细的设计,分区可以将大表在物理上分割为多个小表,而在逻辑上仍然作为一个整体存在,这种设计可以提高查询效率,简化数据管理,分区的方式有多种,如范围分区(RANGE)、列表分区(LIST)等,选择哪种方式取决于数据访问的模式和需求。
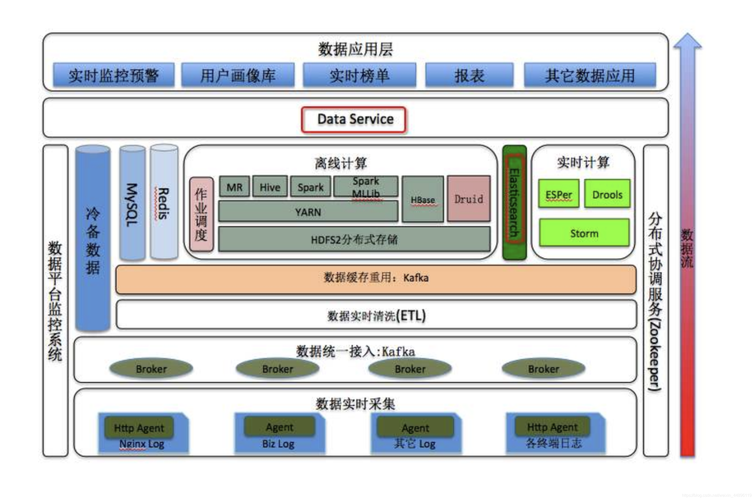
性能优化是大数据量数据库设计中不可忽视的方面,随着数据量的增大,传统的数据库设计和优化方法可能不再适用,自增ID在某些情况下不再是必需的,因为它可能限制了数据并行处理的能力,针对MySQL数据库,可以从多方面进行优化,包括但不限于选择合适的存储引擎、优化数据表的字段顺序、合理使用索引等,这些优化措施能够有效提升数据库的处理能力和响应速度,尤其是在高并发和大数据量的场景下。
考虑到文章的实用性,以下是几个相关问答FAQs,以帮助理解大数据量数据库设计的实际应用:
如何确定是否需要对表进行分区?
答:当一个表的数据量超过500万时,应考虑进行分区,分区可以减少单个表的体积,提高查询效率和管理的便利性,特别是当SQL查询经常依据某列的范围来访问表时,使用RANGE分区是非常合适的。
在哪些情况下自增ID不是一个好的选择?
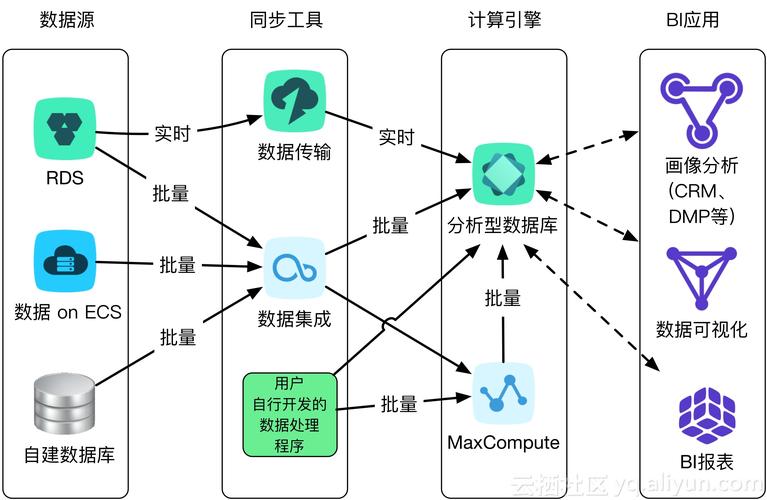
答:在高并发写入和大数据处理的情况下,自增ID可能不是最佳选择,因为它可能限制并行处理的能力,并且随着数据量的增加,可能会遇到性能瓶颈,在这些情况下,可以考虑使用其他类型的ID生成策略,如UUID或自定义算法生成的ID。
大数据量数据库的设计需要综合考虑多方面的因素,包括但不限于数据库结构的合理性、表的分区策略以及针对性能的优化措施,通过合理的设计,不仅可以提高系统的运行效率,还可以保证数据的安全和完整性,为未来的系统维护和升级打下坚实的基础。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/732168.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复