

在机器学习领域,分类问题是其中的一个核心议题,评估一个分类模型的性能时,不仅需要简单明了的指标,还需要能够全面反映模型在不同方面的表现,本文将系统介绍几种常用的综合指标及其适用场景和计算方法。
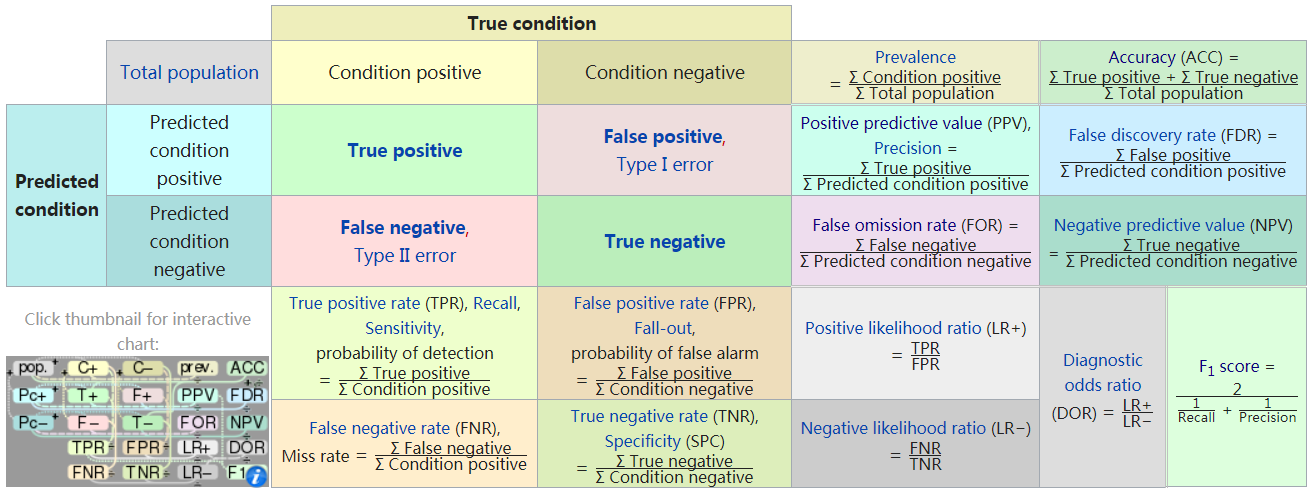
准确率(Accuracy)是最常见的评估指标之一,它表示正确分类的样本数占总样本数的比例,当数据集类别分布均衡时,准确率能较好地反映模型性能,在类别不平衡的情况下,仅凭准确率可能会得出误导性的上文归纳,比如在一个数据集中,如果某个类别的样本数量远多于其他类别,高准确率可能只是由于模型很好地预测了这个多数类,而忽视了少数类,准确率虽直观,但应谨慎使用,特别是在处理不平衡数据集时。
精确率(Precision)和召回率(Recall)是两个不可分割的指标,它们分别衡量了模型在预测正类时的精确度和召回能力,精确率关注的是预测为正类的样本中真正为正类的比例,而召回率则是真实为正类的样本中被正确预测出来的比例,通常情况下,精确率和召回率需要同时考虑,因为它们之间可能存在权衡关系:提高一个可能会导致另一个下降,这种权衡关系可以通过PR曲线(PrecisionRecall Curve)来可视化,该曲线描绘了在不同阈值设置下精确率和召回率的变化情况。
F1分数是精确率和召回率的调和平均数,它试图在两者之间取得平衡,当精确率和召回率都很重要,且希望综合考虑这两个指标时,F1分数是一个不错的选择,一个较高的F1分数意味着模型具有较高的精确率和召回率。
ROC曲线(Receiver Operating Characteristic Curve)和AUC(Area Under the ROC Curve)是用来评估分类模型性能的另一组重要工具,尤其适用于二分类问题,ROC曲线描绘了在不同分类阈值下,模型的真正率(True Positive Rate, TPR)和假正率(False Positive Rate, FPR)之间的权衡,AUC值则表示ROC曲线下的面积,面积越大,说明模型的分类性能越好,AUC值不依赖于特定的分类阈值,因此它是一个较为稳健的性能度量指标。
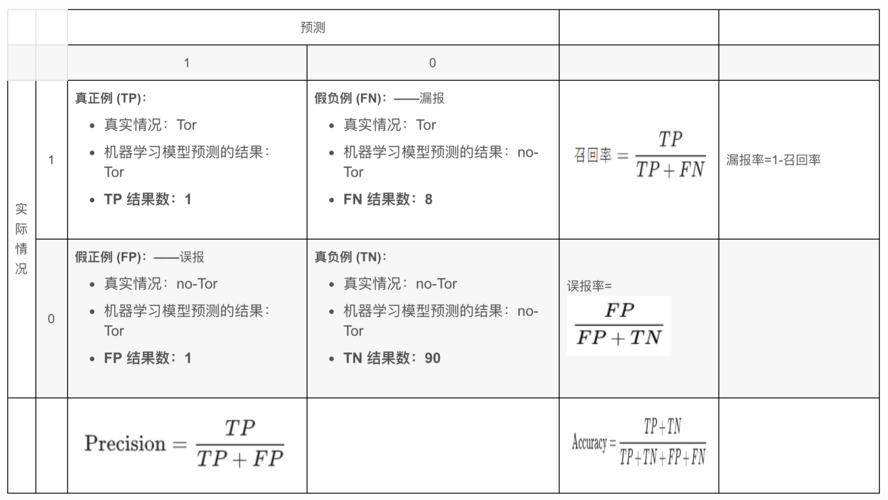
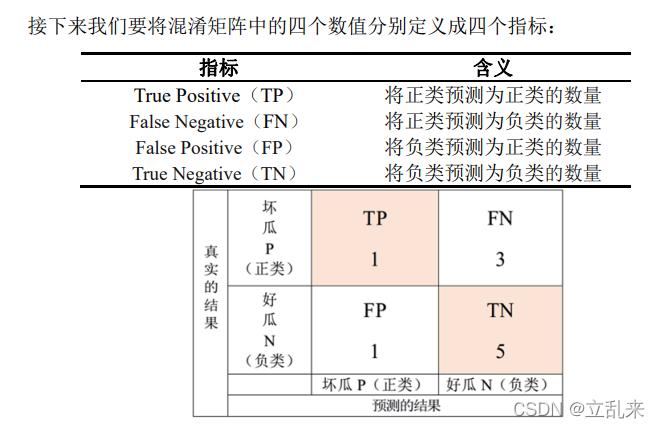
值得一提的是,混淆矩阵(Confusion Matrix)是一个包含所有上述指标信息的表格,它详细展示了模型在各个类别上的预测结果,通过混淆矩阵,可以直观地看到真阳性(True Positive, TP)、假阳性(False Positive, FP)、真阴性(True Negative, TN)和假阴性(False Negative, FN)的数量,从而计算出精确率、召回率等指标,混淆矩阵是理解分类模型性能的一个全面工具。
选择合适的机器学习分类的综合指标对于正确评估模型性能至关重要,每种指标都有其适用场景和局限性,因此在实际应用中需要根据具体问题的特点和数据分布来灵活选择和综合运用这些指标。
相关问答FAQs
Q1: 如何处理类别不平衡的数据集?
A1: 在类别不平衡的情况下,单纯依赖准确率可能会导致误导,可以采用过采样或欠采样技术来调整数据集,使其更加均衡;或者使用如AUC这样的指标,这些指标对类别不平衡较为稳健。
Q2: 如何选择合适的分类评估指标?
A2: 选择分类评估指标时应考虑数据集的特点(如是否均衡)、业务需求(重视精确率还是召回率),以及模型的使用场景,若业务更关注于减少误报,则应重视精确率;若关注于发现所有相关案例,则应重视召回率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/731920.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

发表回复