

排序测试用例_排序
在软件测试中,对排序功能的正确性进行验证是至关重要的,排序测试用例设计旨在确保应用程序能够按照预期正确地排序数据,以下是设计和执行排序功能测试用例时应考虑的关键要素。
理解排序算法
理解应用程序中使用的排序算法(如快速排序、归并排序、冒泡排序等)对于设计有效的测试用例至关重要,不同的算法可能在处理特定类型的数据集时表现出不同的效率和准确性。
确定输入范围
测试用例应覆盖各种可能的输入情况,包括:
空列表或数组
包含单个元素的列表或数组
包含重复元素的列表或数组
已经排序的列表或数组(升序或降序)
随机顺序的列表或数组
包含极端值(如最大和最小可能值)的列表或数组
包含不同数据类型(如果适用)的列表或数组
定义输出期望
对于每个测试用例,必须明确定义排序后的期望结果,这通常意味着知道正确的排序顺序,无论是升序还是降序。
考虑边界条件
边界条件的测试用例应该被设计来检查排序算法在极限情况下的表现,
处理能力极限(如排序大量数据)
性能极限(如排序速度)
数据类型和格式的限制(如排序字符串与数字混合的列表)
编写测试用例
根据上述信息编写具体的测试用例,每个测试用例应详细说明输入数据、预期结果以及如何执行测试。
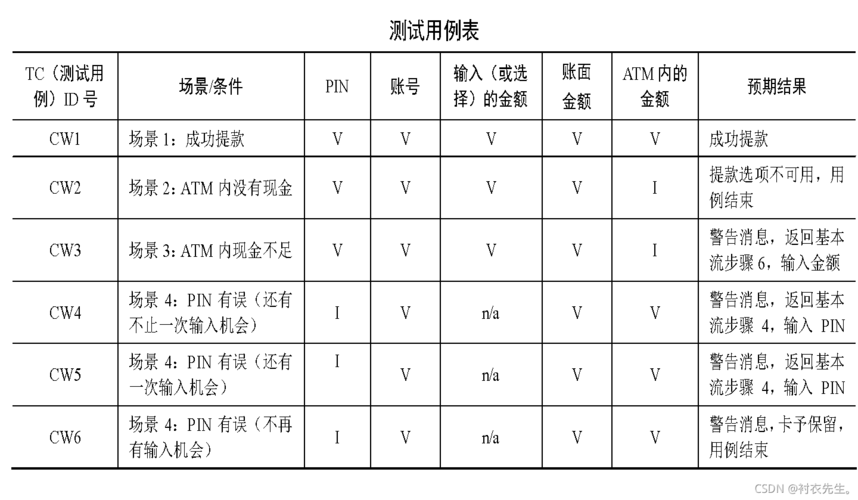
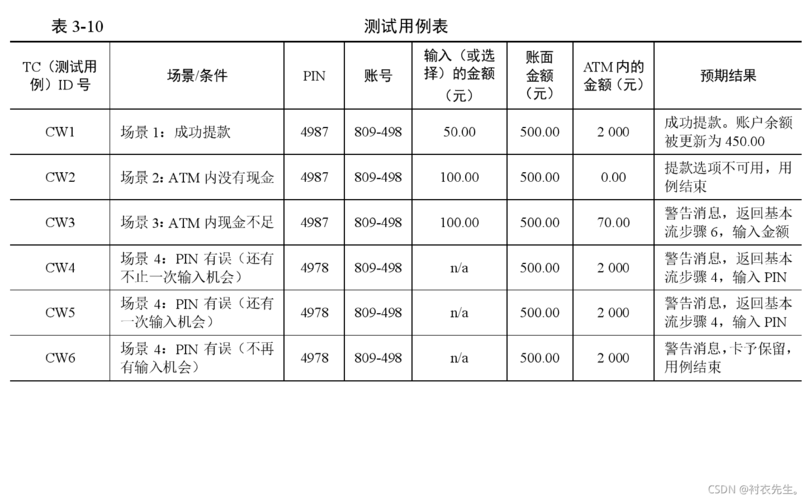
示例测试用例表
| ID | 输入 | 预期结果 | 备注 |
| 1 | 空列表 | 保持不变 | |
| 2 | 单元素列表(如 [5]) | 保持不变 | |
| 3 | 多元素列表(如 [3, 1, 4, 1, 5]) | 升序排列 [1, 1, 3, 4, 5] | 默认为升序排序 |
| 4 | 已排序列表(如 [1, 2, 3, 4, 5] 升序) | 保持不变 | |
| 5 | 包含重复元素的列表(如 [2, 2, 1, 3, 3]) | 升序排列 [1, 2, 2, 3, 3] | |
| 6 | 包含字符串和数字的列表(如 [“apple”, “banana”, 3, 1]) | 错误/异常处理 | 数据类型不一致 |
| 7 | 大数据量测试(如 1000000 个随机整数) | 正确排序且在合理时间内完成 | 性能测试 |
| 8 | 包含极端值的列表(如 [Int32.MinValue, Int32.MaxValue, 0]) | 正确排序 | 边界值测试 |
执行测试
使用自动化测试工具或手动过程执行这些测试用例,并记录结果,确保所有测试用例都按预期执行,任何偏差都应记录下来供进一步分析。
分析结果
分析测试结果,确定排序实现是否满足要求,失败的测试用例应导致对排序实现的修改,然后重新运行测试以确认问题已解决。
维护测试用例
随着应用程序的更新和改进,测试用例也应相应更新以反映新的功能需求和边界条件。
相关问答FAQs
Q1: 如果排序算法在处理极大数据集时出现性能下降,该如何优化?
A1: 性能下降可能是由于算法的时间复杂度较高或者资源利用不当,可以尝试以下几种方法来优化:
选择更高效的算法:比如使用时间复杂度较低的算法(如快速排序代替冒泡排序)。
优化现有算法:通过减少不必要的计算和改进数据结构来提升性能。
并行处理:如果系统资源允许,可以考虑使用并行或分布式排序算法来加快排序过程。
硬件升级:增加更多的内存或更快的处理器可能会提高处理大数据集的能力。
Q2: 如何处理多种数据类型混合的排序需求?
A2: 当涉及到多种数据类型时,排序逻辑需要特别设计以适应不同的比较规则:
自定义比较逻辑:为不同的数据类型定义比较规则,并在排序算法中应用这些规则。
类型转换:在可能的情况下,将不同类型的数据转换为统一的格式(如字符串),然后进行排序。
分层排序:先按类型分组,再在每个组内部进行排序,最后合并各组结果。
用户定义的排序:允许用户指定特定字段或属性作为排序依据,并为这些字段提供适当的比较函数。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/731794.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。