


在现今大数据时代,机器学习的应用越来越普遍,PySpark作为一种大数据处理和分布式计算工具,其在机器学习领域的应用也日渐增多,本文旨在全面介绍使用PySpark构建端到端机器学习场景的全过程,从数据预处理到模型训练,再到模型评估和部署,每一步都至关重要,具体如下:

1、环境准备
安装与配置:首先需要在环境中安装PySpark,安装过程通常包括Java和Scala的运行环境配置以及Spark本身,还需要确保Hadoop系统的相关配置正确,因为Spark默认在Hadoop上存储数据。
基础认识:了解PySpark中的基本概念如RDD(弹性分布式数据集)、DataFrame和Dataset,这些都将直接影响后续数据处理和模型训练的效率和效果。
2、数据处理
数据加载:使用PySpark读取数据,这些数据可以来源于本地文件、HDFS、或其他支持的数据源,数据的加载通常是通过SparkSession对象的read方法实现。
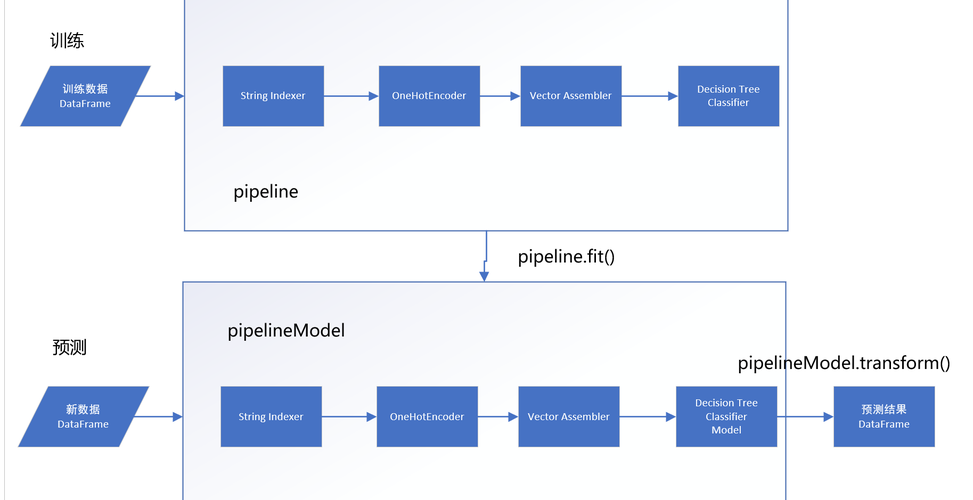
数据预处理:原始数据往往需要进行预处理才能用于训练,在PySpark中,可以使用Transformer进行特征转换,例如使用StringIndexer进行文本数值化,OneHotEncoder进行独热编码等操作。
3、模型训练
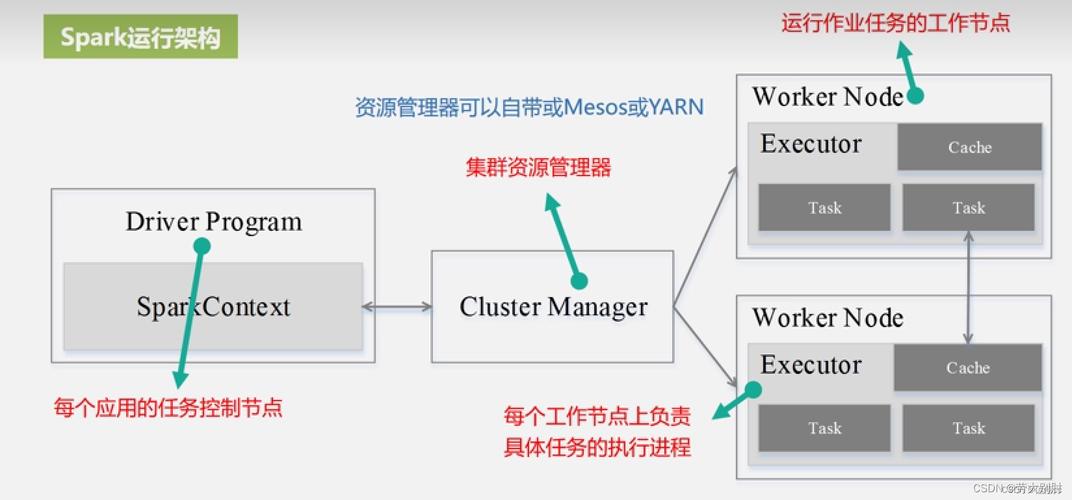
选择算法:根据问题的类型选择合适的机器学习算法,PySpark.ml提供了包括分类、回归、聚类等多种类型的算法。
超参数调优:使用GridSearch或CrossValidation等方法对模型的超参数进行调优,以达到更好的预测性能。
模型训练:利用Estimator进行模型的训练,这包括了数据的拟合和参数的优化。
4、模型评估
评估指标:选择合适的评估指标,如准确率、召回率、F1分数等,来评价模型的性能。
交叉验证:运用交叉验证等技术来评估模型的泛化能力,避免过拟合。
误差分析:对模型的预测结果进行误差分析,找出可能的问题并进行调整。
5、模型部署
模型持久化:训练好的模型可以通过save方法保存到文件系统中,以便后续使用。
模型加载:在实际应用中,通过load模型方法加载训练好的模型进行预测。
6、实验结果与应用
案例分析:通过具体案例分析模型的应用效果,如何在实际业务场景中发挥作用。
优化策略:根据实际应用反馈继续优化模型,调整预处理步骤或重新训练模型以提升效果。
在构建机器学习流水线的过程中,还需要注意以下几个重要方面:
数据质量的保证是前提,需要关注数据的完整性、准确性和一致性。
特征工程是提高模型性能的关键,合适的特征选择和转换可以大幅提升模型表现。
模型的选择和调优需要根据具体问题来定,没有最好的模型,只有最合适的模型。
结合上述信息,使用PySpark构建端到端的机器学习流水线是一个涉及多个环节的复杂过程,从环境的准备到数据处理,再到模型的训练、评估和部署,每一步都需要精心设计和执行,通过实例分析和不断的优化,可以逐渐提升模型的业务应用价值,实现大数据环境下的高效机器学习。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/731522.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复