


迭代MapReduce概念

迭代MapReduce是传统MapReduce框架的延伸,旨在支持需要多轮处理的数据分析任务,在传统的MapReduce操作模型中,数据通过一个Map阶段和一个Reduce阶段进行处理,生成输出结果,对于某些算法,如机器学习、图算法等,需要多次迭代处理才能达到预期的精度或结果,迭代MapReduce为这类需求提供了有效的解决方案。
迭代过程中的主要步骤
1. Read阶段
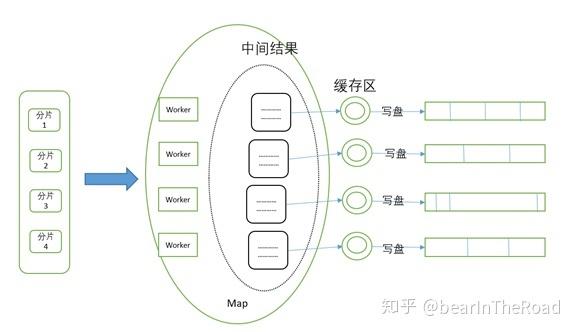
在Read阶段,MapTask使用用户定义的RecordReader解析输入的数据块(InputSplit),生成一系列键值对(key/value)供后续处理。
2. Map阶段
Map阶段的核心在于用户自定义的map()函数,该函数接收解析出的键值对,并对其进行处理,每个Map Task处理一个数据块,并将中间结果存储在本地磁盘上。
3. Shuffle and Sort阶段
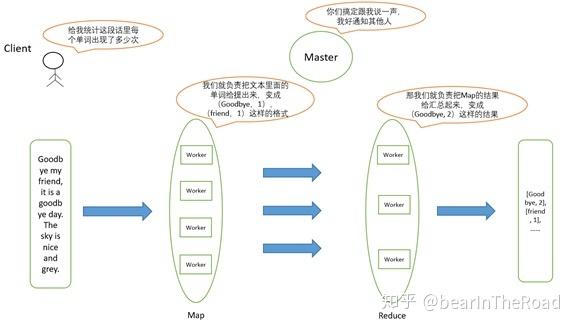
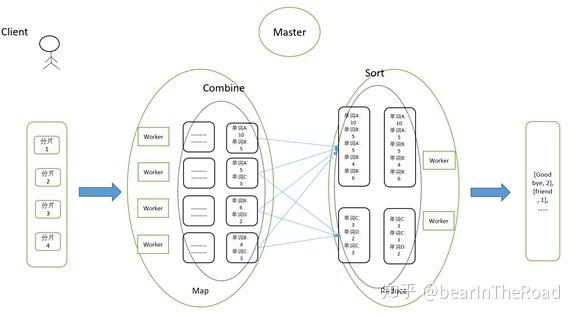
这个阶段是连接Map和Reduce阶段的桥梁,过程中,系统会将Map阶段的输出根据key进行排序和分组,确保相同key的值被分发到同一个Reduce Task。
4. Reduce阶段
在Reduce阶段,每个Reduce Task会接收到一组具有相同key的键值对,用户定义的reduce()函数将被用于处理这些数据,输出最终结果。
5. 迭代控制
在迭代MapReduce中,上述过程可能重复执行多次,直到满足停止条件,这要求框架能够有效地管理中间数据和状态信息,以减少重复计算和数据移动的开销。
迭代MapReduce的特点与优势
高效性:通过在MapReduce框架内集成迭代控制,减少了数据在不同作业之间的读写和传输成本。
易用性:用户只需定义Map和Reduce函数及迭代停止条件,无需关心底层的数据流和迭代控制逻辑。
灵活性:适用于多种需要迭代处理的复杂算法,如PageRank、Kmeans聚类等。
技术实现与挑战
迭代MapReduce的实现涉及多个方面的优化,包括高效的数据存储访问、任务调度优化、以及网络和I/O资源的高效利用,如何减少每次迭代中的数据处理延迟、如何动态调整资源分配也是实现中的关键挑战。
相关技术对比
与传统的批处理MapReduce作业相比,迭代MapReduce在处理大量迭代次数的作业时显示出更高的效率和更好的资源利用率,尽管存在诸多优势,但在某些场景下,例如需极快速响应的实时处理系统中,其他模型如流处理框架可能更为适用。
未来发展方向
随着计算需求的多样化和数据处理技术的不断进步,迭代MapReduce的未来发展方向包括提升处理速度、增强容错能力、提高资源管理的灵活性等,整合AI技术以自动优化任务执行也是潜在的研究方向。
FAQs
什么是迭代MapReduce?
迭代MapReduce是针对需要多次迭代处理的数据分析任务设计的计算框架,它通过在传统的Map和Reduce阶段基础上加入迭代控制逻辑,允许在同一作业内进行多轮数据处理。
迭代MapReduce有哪些应用场景?
迭代MapReduce广泛应用于机器学习、图算法等领域,如PageRank、Kmeans聚类等需要反复迭代以逐步求精的算法中表现出色。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/730312.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复