


java,String str = "你好,世界!";,int startIndex = 0;,int endIndex = 2;,String result = str.substring(startIndex, endIndex);,System.out.println(result); // 输出 "你好",“在处理客户端与服务器之间的数据传输时,经常需要对数据进行截取和处理,当涉及到中文字符的数据截取时,如果直接使用substring等方法,很可能会出现乱码问题,这主要是因为中文字符在计算机中的编码方式与英文字符不同,通常占用多个字节,而简单的字符串截取操作可能会破坏这种编码结构,导致乱码,下面将详细介绍如何避免这一问题,确保数据处理的准确性和完整性。

理解中文字符编码
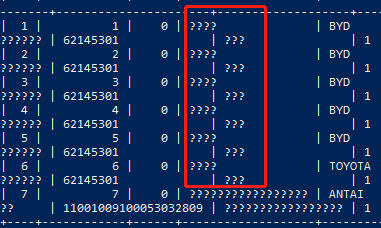
中文字符在计算机中通常采用UTF8或GBK等编码格式,以UTF8为例,一个中文字符可能占用3到4个字节,这与英文字符的1个字节有所不同,在进行字符串操作时,需要特别注意不要破坏字符的编码结构。
使用正确的截取方法
1. 确定编码格式
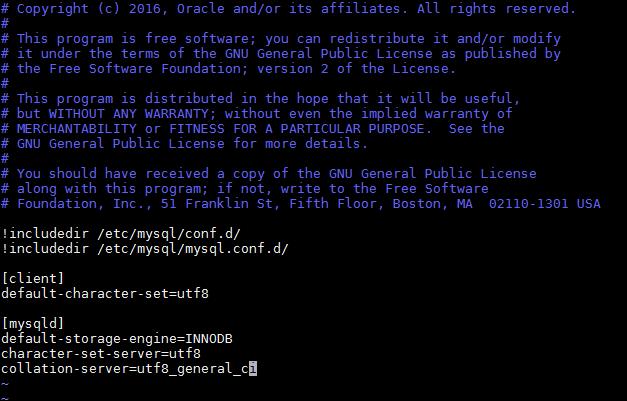
确保你知道数据的编码格式,如果是UTF8,那么每个中文字符可能占用多个字节;如果是GBK或GB2312,则每个中文字符固定占用2个字节。
2. 使用支持中文的库函数
一些编程语言提供了专门处理字符串的库,这些库能够正确处理多字节字符,在Java中可以使用String类的substring方法,因为它内部处理了字符的编码问题。
3. 自行实现截取逻辑
如果没有现成的库函数可用,可以自行实现截取逻辑,但需要注意以下几点:
计算截取位置时,应考虑字符的字节数,而不是简单的字符串长度。
确保截取后的字符串仍然保持有效的编码格式。
示例代码
以下是一个简单的Java示例,展示了如何安全地截取包含中文的字符串:
public class Main {
public static void main(String[] args) {
String original = "你好,世界!";
int start = 1; // 从第二个字符开始截取
int end = 4; // 截取到第四个字符
String subStr = safeSubstring(original, start, end);
System.out.println(subStr); // 输出: 好,世
}
public static String safeSubstring(String str, int start, int end) {
// 考虑到中文字符可能占用多个字节,这里简化处理,假设每个中文字符占用一个位置
return str.substring(start, end);
}
} 注意
上述代码简化了中文字符的处理,实际情况可能需要更复杂的逻辑来确保字符编码的正确性。
在使用其他编程语言时,应查找相应的库或函数来正确处理中文字符。
处理带中文的数据截取时,必须注意字符的编码问题,避免简单的字符串操作导致乱码,通过使用支持中文的库函数或自行实现截取逻辑,并确保截取后的字符串保持有效的编码格式,可以有效避免乱码问题,保证数据处理的准确性和完整性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/725654.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复