


机器学习是现代数据分析和人工智能的核心技术,它使得计算机能够在没有明确编程的情况下预测数据和做出决策,常用的机器学习算法包括多种类型,如回归分析、决策树和支持向量机等,这些算法在端到端场景中的应用涉及多个环节,包括数据预处理、模型选择、训练和服务部署等步骤,本文将详细解析常用的机器学习算法及其在端到端场景中的实际应用。

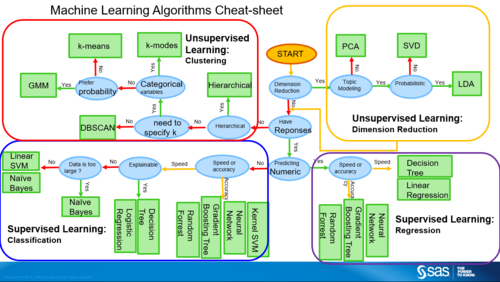
常用机器学习算法
1、线性回归:线性回归是最基础的预测模型之一,适用于连续数据的预测问题,通过拟合数据点来找到最佳拟合线,从而进行数值预测。
2、逻辑回归:与线性回归不同,逻辑回归主要用于分类问题,特别是二分类问题,它将输出变量通过逻辑函数转化为概率值,常用于疾病诊断或垃圾邮件识别等。
3、决策树:决策树是一种非线性的分类方法,通过学习数据的特征,构建树形结构来进行决策制定,它易于理解和实现,但容易过拟合。
4、支持向量机(SVM):SVM是一种效果显著的分类技术,通过寻找最优的超平面来区分不同类别的数据点,尤其适用于高维数据。
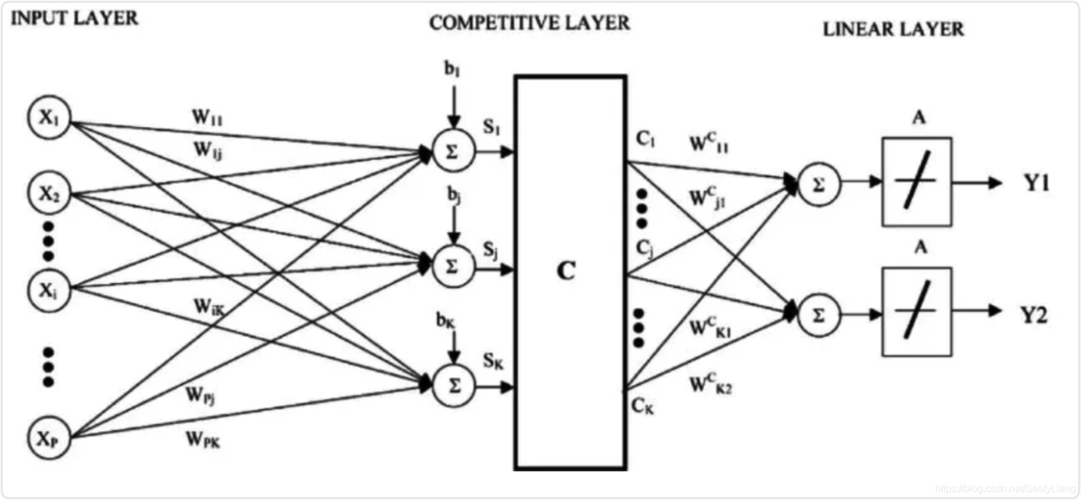
5、神经网络:尽管传统神经网络在处理大规模数据时可能不如其他算法高效,但它们为理解更复杂的深度学习算法奠定了基础,神经网络由多个神经元层组成,可以模拟人类大脑的信息处理方式。
端到端机器学习场景
1、数据预处理:数据预处理是机器学习中非常重要的一步,包括数据清洗、特征选择和归一化等操作,良好的数据预处理能够显著提升模型的性能和准确度。
2、模型选择与训练:根据具体问题选择合适的机器学习算法,对于连续的数据预测,可以选择线性回归;对于分类问题,则可能选择逻辑回归或决策树,模型训练涉及参数调整和交叉验证等步骤,以确保模型具有良好的泛化能力。
3、模型评估:模型评估是通过测试数据集来评价模型性能的过程,常见的评估指标包括准确率、召回率和F1分数等,这一步骤确保所选模型能在未知数据上表现良好。
4、服务部署:模型训练完成后,需要将其部署到生产环境中,这可能涉及到模型的封装、API设计以及与现有系统集成等问题。
5、监控与维护:端到端机器学习过程还包括模型的持续监控和维护,随着时间推移,模型可能会因数据分布的变化而性能下降,因此需要进行定期的重新训练和优化。
相关问答FAQs
Q1: 如何选择合适的机器学习算法?
A1: 选择机器学习算法时需要考虑数据的类型(如标签数据或无标签数据)、问题的复杂度(如是分类还是回归问题)、数据的规模以及计算资源等因素,也需考虑模型的可解释性和实现难度。
Q2: 如何避免模型过拟合?
A2: 过拟合可以通过增加数据量、使用正则化技术、选择更简单的模型或者应用交叉验证等方法来避免,集成学习方法如随机森林也是减少过拟合的有效策略。
归纳而言,了解并选择恰当的机器学习算法,结合严格的数据处理和模型评估流程,可以有效地解决实际问题,通过整个端到端的学习过程,从数据预处理到模型部署,每一步都需要精心设计和执行,以确保最终的模型既准确又可靠。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/724747.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复