

客户端如何请求服务器端的 JavaScript 文件
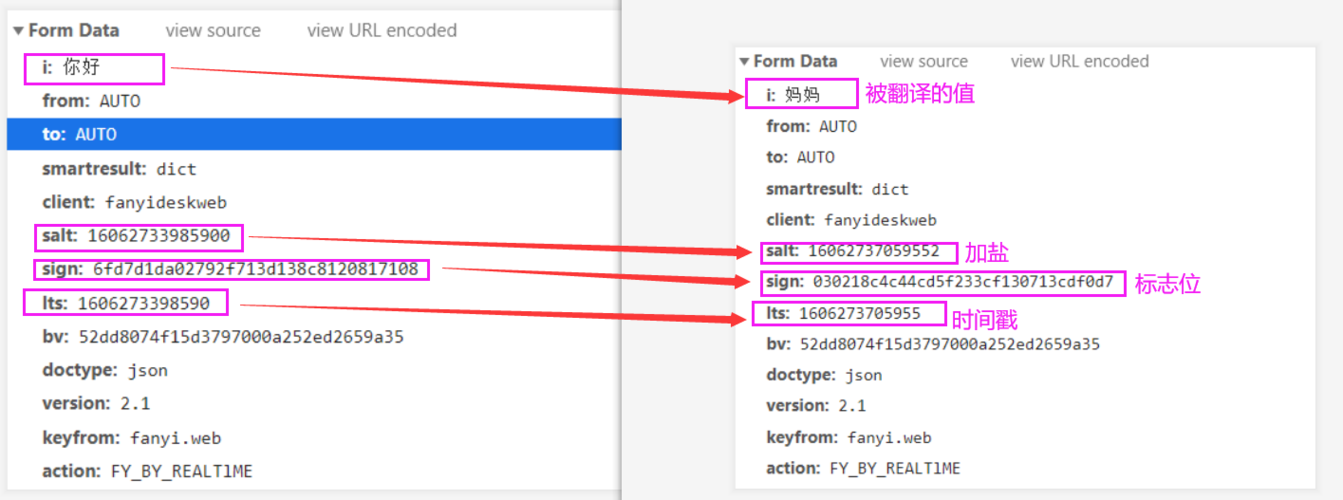
客户端与服务端交互基础
1、Cookie使用:客户端通过存储在本地的Cookie与服务器进行信息交换,从而实现状态保持和数据同步。
2、隐藏框架:利用隐藏的HTML框架或iframe实现与服务端的数据交互,通常用于后台数据处理。
3、HTTP请求:通过发送HTTP请求直接向服务器请求数据,这是最常规的数据获取方式。
4、LiveConnect请求:允许JavaScript代码与Java applet通信,从而实现更复杂的客户端服务端交互。
5、智能HTTP请求:现代Web应用中,通过Ajax等技术异步更新部分页面内容,无需重新加载整个页面。
JavaScript文件获取方法
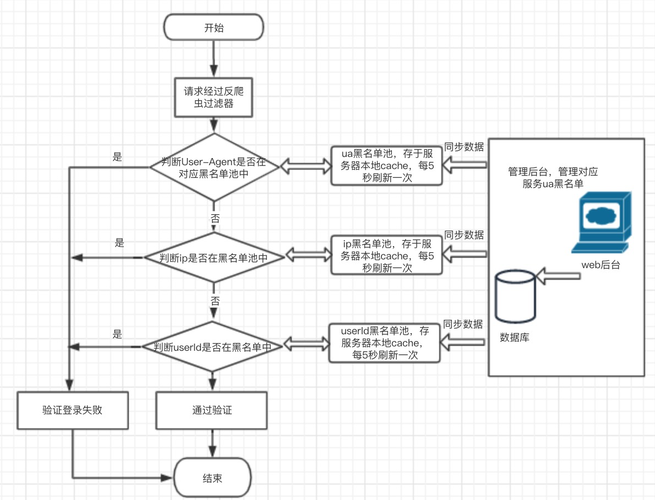
1、XMLHttpRequest对象:允许客户端通过JavaScript发起HTTP请求,并更新页面部分内容。
2、Fetch API:现代Web API,提供更强大、灵活的数据请求和响应处理能力。
3、Node.js的fs模块:服务器端JavaScript运行环境,提供读取文件的接口和方法。
JS脚本反爬虫的检测机制
1、混淆加密工具:通过对JS代码进行混淆和加密,增加爬虫解析难度,提高接口安全性。
2、动态数据验证:JS脚本可以生成动态数据验证任务,要求用户或爬虫完成特定行为以证明非自动化程序。
3、字体映射技术:利用自定义字体文件和字符映射规则,改变网页数据显示方式,增加爬虫识别难度。

4、时间依赖性变换:根据当前时间生成线性变换方程,对字符进行转换,增加解析复杂度。
反爬虫策略效果评估
1、事件统计:通过记录“JS挑战”和“JS验证”事件,统计反爬虫防御请求次数,评估反爬虫策略的有效性。
2、拦截率误伤率:评估反爬虫策略的成功拦截率和误伤率,确保策略的合理性和有效性。
突破反爬虫机制
1、Selenium策略:模拟真实用户操作,通过自动化测试工具Selenium绕过JS脚本执行的反爬虫机制。
2、HTTPS协议限制:通过使用HTTPS协议加强数据传输安全,限制非法请求。
3、请求次数限制:单位时间内限制过多请求次数,防止爬虫批量获取信息。
JavaScript在客户端与服务端交互中发挥着关键作用,不仅能够实现数据的动态获取和页面内容的局部更新,还能通过各种反爬虫技术增强网站的安全性,了解这些技术和策略对于开发和维护现代Web应用至关重要,随着技术的发展,客户端和服务端之间的交互方式将更加多样化和复杂化,需要开发者不断学习和适应新的技术环境。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/724049.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复