


排序时间复杂度_排序

在计算机科学中,排序算法是处理数据时不可或缺的一部分,它们的主要目标是将一组无序的元素转换为有序的序列,不同的排序算法具有不同的性能特征,其中最显著的性能指标之一就是时间复杂度,时间复杂度描述了算法执行所需时间与输入数据量之间的关系,了解不同排序算法的时间复杂度对于选择合适的算法至关重要,尤其是在处理大量数据时。
常见排序算法及其时间复杂度
以下是一些常见的排序算法以及它们的时间复杂度:
1. 冒泡排序(Bubble Sort)
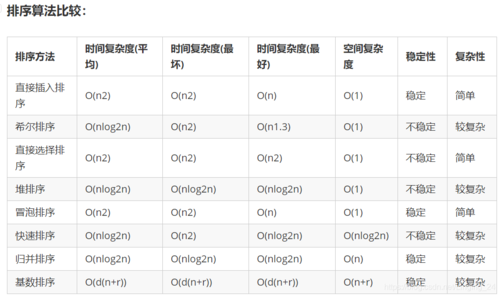
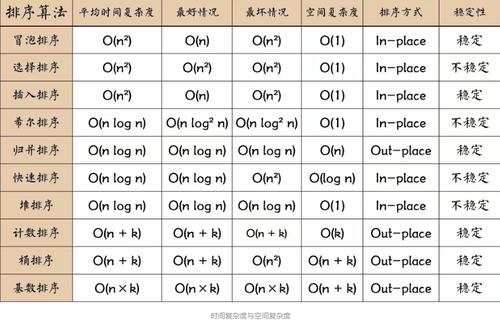
冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来,冒泡排序的平均和最坏情况时间复杂度均为 O(n^2)。
2. 选择排序(Selection Sort)
选择排序也是一种简单直观的排序算法,它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完,选择排序的平均和最坏情况时间复杂度为 O(n^2)。
3. 插入排序(Insertion Sort)
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,插入排序在最坏情况下的时间复杂度为 O(n^2),但在接近有序的情况下可以达到 O(n)。
4. 快速排序(Quick Sort)
快速排序使用分治法的一个非常典型的应用,它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,使得整个数据变成有序序列,快速排序的平均时间复杂度为 O(n log n),但在最坏情况下会退化到 O(n^2)。
5. 归并排序(Merge Sort)
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用,作为一种典型的空间换时间的策略,它将数组分为两半,分别对每部分递归地应用排序,然后将两个已排序的半部分合并在一起,归并排序在所有情况下的时间复杂度都是 O(n log n)。
6. 堆排序(Heap Sort)
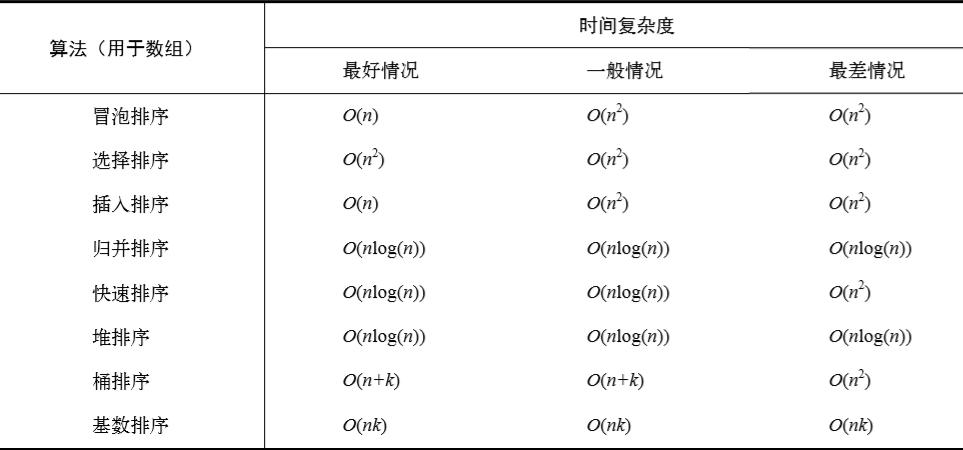
堆排序是指利用堆这种数据结构所设计的一种排序算法,堆排序是一种选择排序,它的工作原理是首先将待排序的序列构造成一个大顶堆,整个序列的最大值就是堆顶的根节点,将其与末尾元素进行交换,然后将剩余的n1个元素重新构造成一个堆,以此类推,得到一个有序序列,堆排序的时间复杂度为 O(n log n)。
相关问答FAQs
Q1: 如何根据具体情况选择适合的排序算法?
A1: 在选择适合的排序算法时,需要考虑以下几个因素:
数据量大小:对于小数据集,简单的算法如冒泡排序、选择排序可能足够且易于实现;对于大数据集,应考虑更高效的算法如快速排序、归并排序或堆排序。
数据的稳定性:如果需要保持等值元素的相对顺序不变,应选择稳定的排序算法,如归并排序、插入排序或冒泡排序。
最坏情况性能:如果输入数据经常处于或接近最坏情况状态,应避免使用快速排序,因为它在这种情况下会退化到 O(n^2)。
额外空间需求:如果内存使用是一个关键问题,应考虑原地排序算法,如快速排序和堆排序。
Q2: 为什么快速排序通常是首选的排序算法?
A2: 快速排序通常是首选的排序算法,原因如下:
平均性能:快速排序的平均时间复杂度为 O(n log n),这使其在大多数情况下都非常高效。
原地排序:快速排序是原地算法,不需要额外的存储空间,这使得它在空间受限的环境中特别有用。
适应性:快速排序能够很好地适应各种输入数据,尽管在最坏情况下性能会下降,但这种情况并不常见。
并行性:快速排序的分区操作可以并行化,这使得它能够利用多核处理器的优势来加速排序过程。
需要注意的是,虽然快速排序通常表现良好,但它并不是所有情况下的最佳选择,在某些特定情况下,其他排序算法可能会更加合适。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/722392.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复