


Kafka 存储 Hadoop SQL on Hadoop
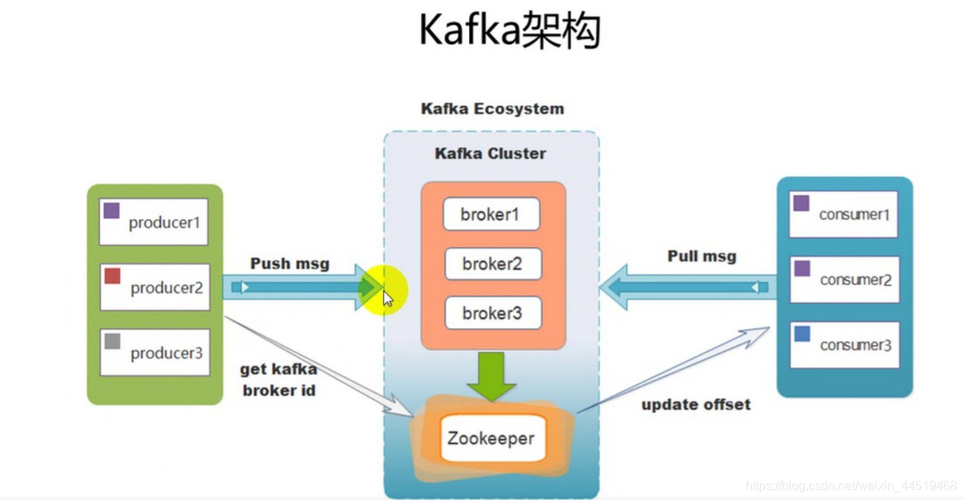

Kafka 是一个分布式流处理平台,用于构建实时数据管道和流应用程序,而 Hadoop SQL 是 Apache Hive 的一个组件,它允许用户使用类似于 SQL 的查询语言来查询和管理 Hadoop 集群中的数据,结合 Kafka 和 Hadoop SQL on Hadoop,可以实现高效的实时数据处理和分析。
以下是一个简单的示例,展示了如何使用 Kafka 存储 Hadoop SQL on Hadoop:
1、安装和配置 Kafka
下载并解压 Kafka 二进制文件
配置 Kafka 服务器和客户端
启动 Zookeeper 和 Kafka 服务器
2、安装和配置 Hadoop
下载并解压 Hadoop 二进制文件
配置 Hadoop 集群(如 HDFS)
启动 Hadoop 集群
3、安装和配置 Hive
下载并解压 Hive 二进制文件
配置 Hive 与 Hadoop 集成
启动 Hive 服务
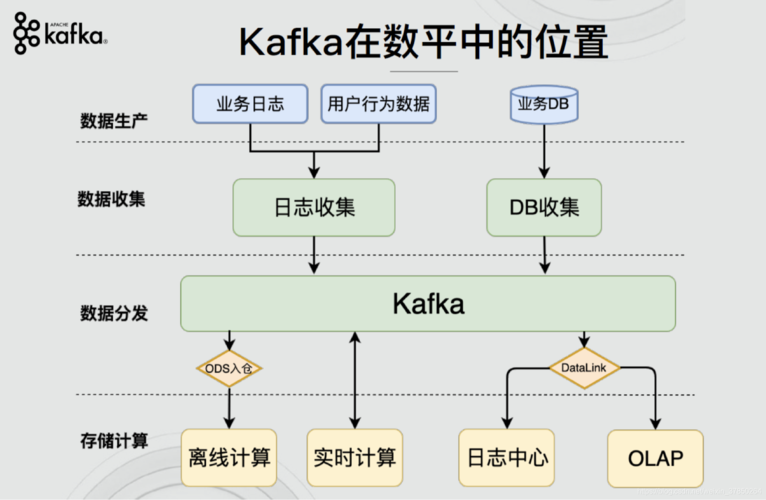
4、创建 Kafka 主题
使用 Kafka 命令行工具创建一个新的主题,kafkatopics.sh create bootstrapserver localhost:9092 replicationfactor 1 partitions 1 topic my_topic
5、编写 Kafka 生产者程序
使用 Java 或其他编程语言编写一个 Kafka 生产者程序,将数据发送到刚刚创建的主题
6、编写 Kafka 消费者程序
使用 Java 或其他编程语言编写一个 Kafka 消费者程序,从主题中读取数据并将其写入 Hadoop HDFS
7、在 Hive 中创建表
使用 HiveQL 创建一个外部表,指向 Hadoop HDFS 上的数据位置
CREATE EXTERNAL TABLE my_table (key string, value string) STORED AS TEXTFILE LOCATION '/path/to/hdfs/data';
8、使用 HiveQL 查询数据
使用 HiveQL 查询刚刚创建的表,SELECT * FROM my_table;
通过以上步骤,您可以实现 Kafka 存储 Hadoop SQL on Hadoop 的功能,这样,您就可以利用 Kafka 的高吞吐量和实时性,以及 Hadoop SQL on Hadoop 的大规模数据处理能力,进行高效的实时数据分析。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/722368.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复