


词法分析器c语言解释 _C#语言


基本原理
词法分析器(Lexical Analyzer)在编译过程中负责首个阶段的工作,其任务是将源代码文本转化为称为“词法标记”(Tokens)的结构化数据流,这些Tokens是按照语言的词法规则从源码中识别出来的,包括关键字、操作符、标识符、常量等元素,在C#语言中,这一过程并无二致,尽管具体实现可能因语言特性而有所差异。
功能与组成
一个基础的词法分析器具有以下功能:
1、关键字识别:如if,else,while等;
2、运算符和界符识别:如+,,{,}等;
3、标识符和数字常量识别:通过正则表达式定义;
4、空白处理:通常忽略空格、制表符和换行符。
为了实现这些功能,词法分析器需要维护若干关键数据结构,包括但不限于关键字表、字符分类表以及用于拼凑和识别Tokens的相关变量和函数。
实现方法
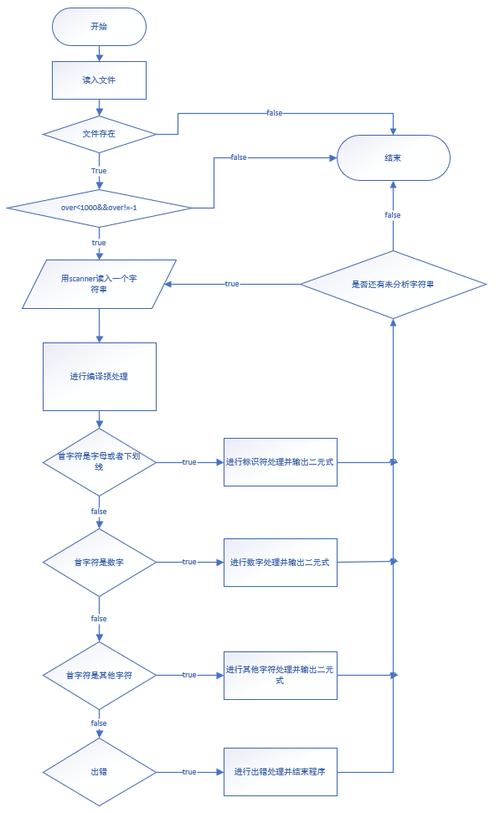
以C语言编写的词法分析器为例,其实现通常包含以下步骤:
1、初始化关键字表:将语言保留字存入数组或哈希表中,以便快速检索;
2、设立状态机:根据文法规则建立状态转换图,用以指导词法分析过程;
3、字符读取与预处理:从源代码中逐个或逐段读取字符,并进行初步过滤;
4、Token拼凑与识别:依据首字符类型,使用状态机拼凑完整Token并识别其类别;
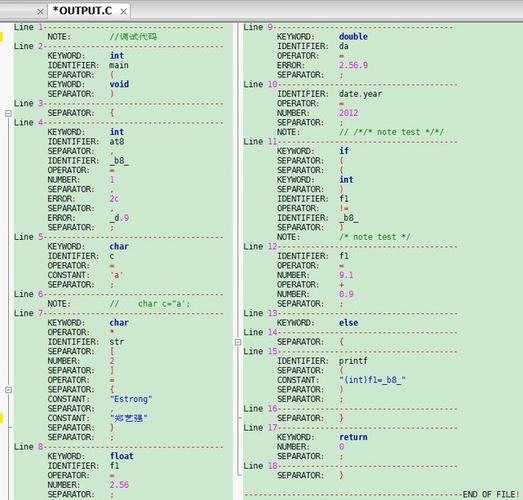
5、输出词法单元:将识别出的Token及其类型编码输出为二元组形式。
应用场景
词法分析器的应用场景广泛,不仅限于编译器设计,它可以被用于:
1、语法高亮显示:在代码编辑器中对不同语法元素进行着色;
2、代码自动完成:提供基于上下文的关键字和API建议;
3、语法错误诊断:在IDE中实时检查并提示潜在的编码错误。
相关问答FAQs
Q1: 如何提高词法分析器的性能?
A1: 提高性能可以从以下几个方面入手:
优化数据结构:使用更高效的数据结构存储关键字表和状态转换图;
减少状态转换次数:设计精简且确定性的状态机,避免不必要的状态转换;
并行处理:对于大规模源代码,考虑采用多线程或分布式处理方式;
缓存机制:引入缓存策略,避免对相同代码段的重复解析。
Q2: 如何处理词法分析中的未知符号?
A2: 面对未知符号,可以采取以下策略:
错误恢复:记录错误位置,并尝试跳过错误符号继续解析后续代码;
用户提示:向用户报告错误位置和可能的原因,请求检查源代码;
容错模式:在可能的情况下,自动修正或忽略未知符号,尽力生成有效的词法单元序列。
词法分析器作为编译过程的门户,承担着将源代码转化为结构化数据的重要任务,无论是在C语言还是C#语言中,其基本原理和工作流程都是相似的,只是具体的实现细节会根据语言特性有所不同,通过精心设计和优化,词法分析器不仅能提升编译器的整体性能,还能增强IDE等开发工具的功能,从而显著提高程序员的开发效率。
下面是一个简化的介绍,展示了如何在C语言和C#语言中实现词法分析器(Lexer)的相关概念。
| 特性/概念 | C语言实现示例 | C#语言实现示例 | |
| 字符输入 | FILE *fp; char ch; ch = fgetc(fp); | StreamReader sr; int ch = sr.Read(); | |
| 读取整个文件 | fread(buffer, 1, fileSize, fp); | sr.ReadToEnd(); | |
| 逐行读取 | fgets(line, MAX_LEN, fp); | while ((line = sr.ReadLine()) != null) { ... } | |
| 判断字符类型 | if (isspace(ch)) /if (isalpha(ch)) /if (isdigit(ch)) | if (char.IsWhiteSpace(ch)) /if (char.IsLetter(ch)) /if (char.IsDigit(ch)) | |
| 令牌枚举 | enum TokenType { ID, NUM, ... }; | public enum TokenType { Id, Number, ... } | |
| 令牌结构 | struct Token { TokenType type; char* value; }; | public class Token { public TokenType Type { get; set; } public string Value { get; set; } } | |
| 令牌数组 | Token tokens[MAX_TOKENS]; | List | |
| 跳过空白符 | while (isspace(ch)) ch = fgetc(fp); | while (char.IsWhiteSpace(ch)) ch = sr.Read(); | |
| 识别标识符 | while (isalpha(ch) | isdigit(ch)) { token.value[i++] = ch; ch = fgetc(fp); } | while (char.IsLetterOrDigit(ch)) { token.Value += ch; ch = sr.Read(); } |
| 识别数字 | while (isdigit(ch)) { token.value[i++] = ch; ch = fgetc(fp); } | while (char.IsDigit(ch)) { token.Value += ch; ch = sr.Read(); } |
| 错误处理 | `fprintf(stderr, "Lexical error at %d
", lineNumber); |Console.Error.WriteLine($"Lexical error at {lineNumber}");` |
请注意,这只是一个简单的示例,实际的词法分析器可能需要处理更复杂的语法,包括字符串字面量、注释、多字符符号(如<=,!= 等)等,在C#中,我们通常使用更高级的API,如正则表达式或状态机(Finite State Machine, FSM),来简化词法分析任务。
在C语言中,你需要手动处理内存分配和释放,而在C#中,有垃圾收集器(Garbage Collector, GC)来帮助管理内存,使得代码更加简洁,上面的示例展示了两种语言在实现词法分析器时的一些基本差异。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/720812.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复