


SQLAlchemy


SQLAlchemy 是 Python 中一款非常流行的数据库工具包,它对底层的数据库操作提供了高层次的抽象,该工具包含两个主要组成部分:SQL 工具包和对象关系映射器(ObjectRelational Mapper, ORM)。
1、安装和设置:
安装 SQLAlchemy 非常简单,可以通过 pip 工具进行安装:
“`bash
pip install sqlalchemy
“`
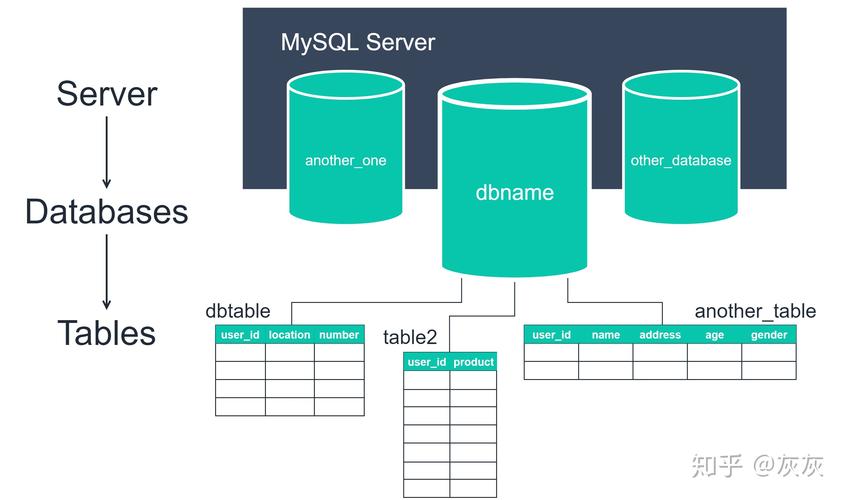
需要设置一个 SQLAlchemy Engine,Engine 是 SQLAlchemy 中的一个核心接口,为 SQL 数据库提供了一种统一的方式来与 Python 程序进行交互,以下是一个 SQLite 数据库的 Engine 设置示例:
“`python
from sqlalchemy import create_engine
# 创建一个内存中的 SQLite 数据库
engine = create_engine(‘sqlite:///:memory:’, echo=True)
“`
2、SQLAlchemy SQL 工具包的使用:
SQLAlchemy 的 SQL 工具包提供了一种 Pythonic 的方式来生成和执行 SQL 语句,可以使用以下代码来创建一个新的数据库表:
“`python
from sqlalchemy import Table, Column, Integer, String, MetaData
metadata = MetaData()
users = Table(
‘users’, metadata,
Column(‘id’, Integer, primary_key=True),
Column(‘name’, String),
Column(’email’, String),
)
metadata.create_all(engine)
“`
3、SQLAlchemy ORM 的使用:
SQLAlchemy 的 ORM 允许将 Python 类映射到数据库表,使得能够使用面向对象的方式来处理数据库,以下是一个简单的 ORM 示例:
“`python
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = ‘users’
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(String)
Base.metadata.create_all(engine)
“`
在上面的代码中,定义了一个 User 类,并将其映射到 users 表,可以使用类和对象的方式来操作数据库:
“`python
from sqlalchemy.orm import Session
# 创建一个新的 Session
session = Session(engine)
# 创建一个新的 User 对象
new_user = User(name=’John’, email=’john@example.com’)
# 添加到 session
session.add(new_user)
# 提交(保存)更改
session.commit()
“`
4、:
SQLAlchemy 是一个强大的工具,使得处理数据库变得更简单、更 Pythonic,通过学习 SQLAlchemy 的基础知识,包括如何安装和设置 SQLAlchemy,以及如何使用 SQLAlchemy 的 SQL 工具包和 ORM,可以有效提升数据库操作的效率和质量,在接下来的学习中,可以深入探索 SQLAlchemy 的高级特性,如事务管理、表关联等。
pydbclib
pydbclib 是一个通用的 Python 关系型数据库操作工具包,使用统一的接口操作各种关系型数据库(如 Oracle、MySQL、Postgres、Hive、Impala 等),它是对各个 Python 数据库连接驱动包(如 SQLAlchemy、PyMySQL、cx_Oracle、pyhive、pyodbc、impala 等)的封装。
1、安装和设置:
安装 pydbclib 非常简单,可以通过 pip 工具进行安装:
“`bash
pip3 install pydbclib
“`
使用 connect 函数建立与数据库的连接,使用 SQLite 数据库:
“`python
with connect("sqlite:///:memory:") as db:
# 执行数据库操作
“`
2、SQL 操作:
pydbclib 提供了简便的方法来执行 SQL 语句,支持单条和批量执行,创建表并插入数据:
“`python
db.execute(‘create table foo(a integer, b varchar(20))’)
db.execute("insert into foo(a,b) values(:a,:b)", [{"a": 1, "b": "one"}]*4)
“`
查询数据并打印结果:
“`python
print(db.read("select * from foo").get_one())
print(db.read("select * from foo").get_all())
“`
3、表级别操作:
pydbclib 还支持表级别的操作,如插入记录、查询记录等,插入一条记录:
“`python
db.get_table("foo").insert({"a": 1, "b": "one"})
“`
查询记录:
“`python
print(db.get_table("foo").find_one({"a": 1}))
“`
4、:
pydbclib 提供了一个统一的接口来操作多种关系型数据库,简化了数据库操作的复杂性,无论是执行基本的 CRUD 操作还是进行复杂的查询,pydbclib 都能以简洁的方式完成任务,通过进一步学习和使用 pydbclib,可以提升在不同数据库系统中工作的灵活性和效率。
相关问答FAQs
1、SQLAlchemy 和 pydbclib 有什么区别?该如何选择?
SQLAlchemy 是一款功能丰富的数据库工具包,提供了包括 SQL 工具包和 ORM 在内的多种功能,适合需要进行复杂数据库操作的场景,而 pydbclib 则是一个通用的关系型数据库操作工具包,提供统一的接口操作各种关系型数据库,适合需要在多种数据库之间灵活切换的场景,在选择时,如果更倾向于使用面向对象的数据库操作,并且项目较为复杂,可以选择 SQLAlchemy;如果需要在多种数据库之间进行操作,追求接口的统一性,可以选择 pydbclib。
2、使用 SQLAlchemy 或 pydbclib 有什么好处?
使用这些工具包的好处包括:简化数据库操作,减少直接编写 SQL 语句的需要;提供高层次的抽象,使得数据库操作更加 Pythonic;支持多种数据库系统,提高项目的灵活性和可移植性;提供 ORM 等功能,使得可以使用面向对象的方式来处理数据库,提高开发效率和代码可读性。
下面是一个简单的介绍,展示了几个在Python中常用的数据库工具包及其主要功能:
| 数据库工具包 | 简介 | 主要功能 |
| SQLite | Python标准库内置的轻量级数据库,无需额外安装 | 提供简单的数据库操作API 适合小型项目和快速原型开发 |
| MySQL Connector/Python | MySQL官方提供的驱动,用于连接MySQL数据库 | 支持所有MySQL功能 提供事务处理和预处理语句等高级功能 |
| psycopg2 | 用于连接PostgreSQL数据库的Python库 | 支持PostgreSQL的大部分特性 提供高效的数据传输和类型转换 |
| SQLAlchemy | 一个强大的SQL工具包和对象关系映射(ORM)框架 | 提供高级的ORM功能 支持多种数据库后端 提供查询构建器 |
| peewee | 一个简单、轻量级的ORM库,用于小型项目 | 简单易用的API 支持多种数据库后端 支持迁移 |
| Django ORM | Django框架的一部分,提供ORM支持 | 集成在Django框架中 简化数据库操作 支持迁移 |
| Records | 一个简单的SQL库,旨在提供一个轻量级的接口来执行SQL查询并处理结果集 | 简单的查询接口 支持多种数据库后端 自动类型转换 |
| PyMongo | MongoDB的官方Python驱动,用于连接MongoDB数据库 | 提供对MongoDB文档数据库的完整支持 支持MongoDB的所有特性 |
这个介绍简要概述了这些工具包的基本信息,开发者可以根据项目需求选择合适的工具包。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/720752.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复