


PHP抓取网页数据

PHP是一种广泛使用的服务器端脚本语言,它非常适合用于从网页上抓取数据,下面将介绍如何使用PHP来抓取网页数据。
1. 使用file_get_contents()函数
file_get_contents()是PHP中一个简单的函数,可以用来读取一个文件的内容,当用于获取网页内容时,它可以返回整个HTML文档的字符串表示。
<?php $url = 'https://www.example.com'; $htmlContent = file_get_contents($url); echo $htmlContent; ?>
2. 使用cURL库
虽然file_get_contents()很方便,但在某些情况下,如需要处理cookie、设置超时等高级功能时,使用cURL库可能更为合适。
<?php $url = 'https://www.example.com'; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); $htmlContent = curl_exec($ch); curl_close($ch); echo $htmlContent; ?>
3. 解析HTML内容
一旦你有了HTML内容,你可以使用各种方法来解析和提取所需的数据,其中最常用的方法是使用DOMDocument类。
<?php
$htmlContent = file_get_contents('https://www.example.com');
$dom = new DOMDocument();
@$dom>loadHTML($htmlContent);
$xpath = new DOMXPath($dom);
// 示例:提取所有链接
$links = $xpath>query("//a");
foreach ($links as $link) {
echo $link>getAttribute('href') . "n";
}
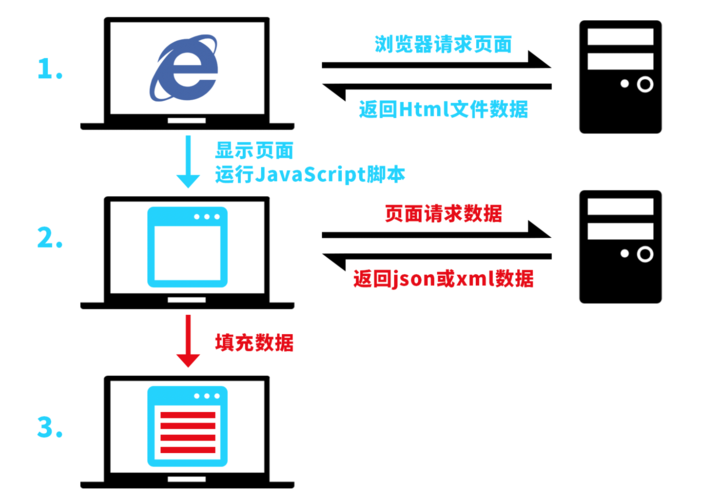
?> 4. 处理JavaScript渲染的内容
许多现代网站使用JavaScript动态加载内容,这使得直接使用上述方法难以获取完整的页面内容,在这种情况下,可以使用像Selenium这样的工具来模拟浏览器行为并获取动态生成的内容。
5. 注意事项
确保遵守网站的robots.txt规则,避免过度抓取导致IP被封禁。
尊重网站的版权和使用条款。
不要滥用抓取功能,例如频繁请求或大规模抓取可能导致法律问题。
FAQs
Q: 如何避免被网站封禁?
A: 遵循网站的robots.txt规则,限制抓取频率,并在请求头中设置合适的UserAgent,确保你的爬虫不会对服务器造成过大负担。
Q: 如何处理JavaScript渲染的内容?
A: 对于JavaScript渲染的内容,可以使用像Selenium这样的工具来模拟浏览器行为,或者寻找其他第三方API服务来提供动态内容的访问。
在PHP中抓取网页数据通常使用cURL库或者file_get_contents函数,下面是一个使用cURL库来获取网页数据,并将数据以介绍形式输出的示例。
确保你的PHP环境已经安装并启用了cURL扩展。
下面是一个简单的PHP脚本,它会获取一个网页(示例中使用一个假设的网址)的内容,并尝试解析其中的数据(这里假设网页以某种方式格式化了一些数据):
<?php
// 初始化cURL会话
$ch = curl_init();
// 设置cURL选项
curl_setopt($ch, CURLOPT_URL, "http://www.example.com/data"); // 设置需要抓取的网页地址
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 将响应作为字符串返回,而不是直接输出
curl_setopt($ch, CURLOPT_HEADER, 0); // 不输出HTTP头
// 执行cURL会话
$response = curl_exec($ch);
// 关闭cURL会话
curl_close($ch);
// 解析网页内容(假设内容是HTML介绍数据)
// 注意:这里的解析依赖于网页的具体内容,以下代码仅为示例
// 实际应用中需要根据网页的结构进行相应的解析处理
// 假设响应是一个JSON,这里使用json_decode来处理
// 如果是HTML,你可能需要使用DOMDocument或者正则表达式来解析
$data = json_decode($response, true);
// 检查是否有错误
if (is_null($data)) {
echo "解码JSON失败: " . json_last_error_msg();
exit;
}
// 开始输出介绍
echo "<table border='1'>";
echo "<tr>";
echo "<th>列标题1</th>";
echo "<th>列标题2</th>";
echo "<th>列标题3</th>";
// 根据你的数据,添加更多的列标题
echo "</tr>";
// 假设每个数据项是一个数组
foreach ($data as $item) {
echo "<tr>";
echo "<td>" . $item['field1'] . "</td>";
echo "<td>" . $item['field2'] . "</td>";
echo "<td>" . $item['field3'] . "</td>";
// 根据实际的数据结构,添加更多的字段
echo "</tr>";
}
echo "</table>";
?> 请注意,上述代码的解析部分是非常简化的,实际情况下你可能需要处理更复杂的HTML结构或者JSON格式,解析HTML时,可以考虑使用DOMDocument 类或者preg_match_all 等正则表达式函数。
确保在抓取数据时遵守目标网站的使用条款,尊重版权和隐私政策,频繁的抓取可能会对目标网站造成负担,应谨慎操作。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/719790.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复