

php反爬虫策略

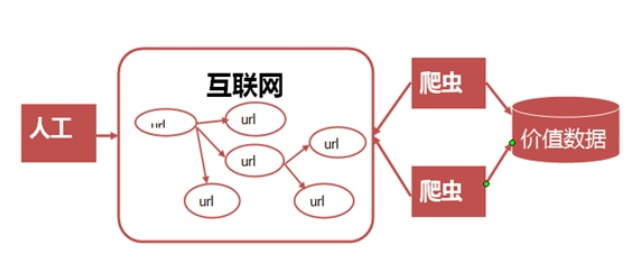
在当今数字化时代,网站安全和数据保护变得尤为重要,网络爬虫的广泛应用使得网站必须采取有效措施防止敏感数据的非授权访问,PHP作为流行的编程语言之一,其安全性对网站的防护至关重要,以下将具体探讨使用PHP进行反爬虫的策略和方法。
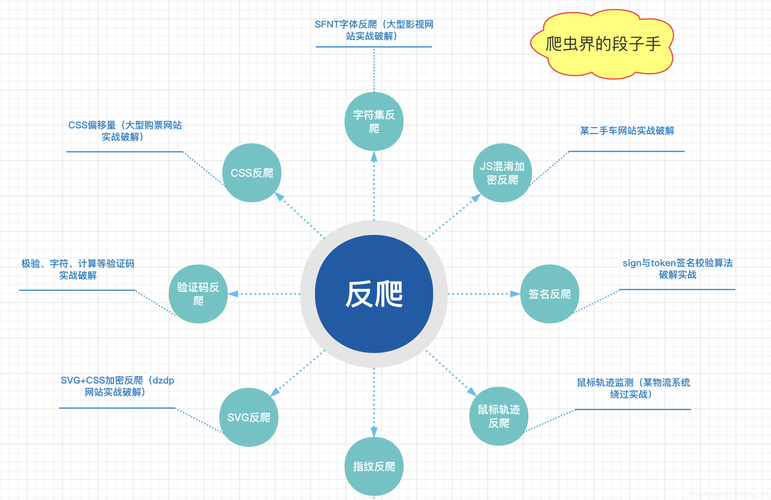
基础知识与常见爬虫类型
1、爬虫定义与作用:
定义:爬虫是自动获取网页内容的程序,广泛应用于数据抓取、信息收集等。
作用:在大数据分析、网络内容监控中发挥重要作用,但也可能用于不正当目的。
2、常见反爬机制:
IP限制:通过限制IP访问频率或禁止特定IP段访问。
用户代理限制:检查HTTP请求中的UserAgent字段,以识别并限制爬虫。
验证码:通过添加验证码或滑块验证防止自动化访问。
动态页面渲染:使用JavaScript渲染页面,阻止爬虫获取内容。
频率限制:监控访问频率,限制短时间内大量请求。
Referer限制:检查HTTP请求的Referer字段,判断请求来源。
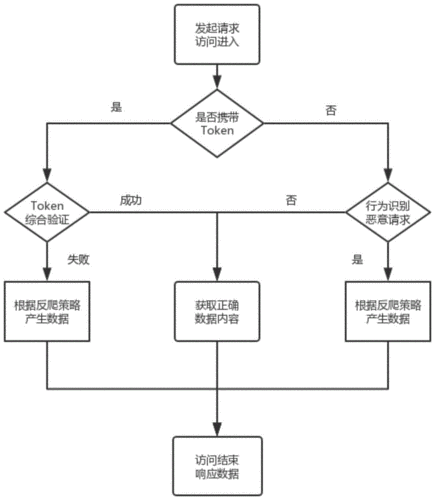
PHP反爬虫处理方法与策略
1、使用代理IP:
方法:通过使用代理IP模拟不同IP地址访问,绕过IP限制。
实例:
“`php
function getData($url, $proxy) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_PROXY, $proxy);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$content = curl_exec($ch);
curl_close($ch);
return $content;
}
“`
2、设置合理的UserAgent:
方法:在爬虫类中设置合理的UserAgent,模拟浏览器行为,绕过用户代理限制。
实例:
“`php
function getRandomUserAgent() {
$userAgents = array(
‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3’,
//…其他UserAgent字符串
);
return $userAgents[array_rand($userAgents)];
}
“`
3、解析和处理验证码:
方法:使用OCR技术或模拟用户交互进行验证码解析。
实例:
“`php
function parseCaptcha($url, $captcha) {
// 使用OCR技术解析验证码
$result = OCR::parse($captcha);
// 或者通过模拟用户交互的方式进行验证码操作
//$result = simulateCaptchaInteraction($url, $captcha);
return $result;
}
“`
4、使用无头浏览器:
方法:使用无头浏览器(如Selenium)解决动态页面渲染问题,模拟浏览器行为获取完整页面内容。
实例:
“`php
function getDynamicContent($url) {
$driver = new ChromeDriver();
$driver>get($url);
$content = $driver>getPageSource();
$driver>quit();
return $content;
}
“`
5、随机请求策略:
方法:在爬虫类中设置请求的随机延时和随机UserAgent,模拟人类请求间隔和行为,绕过频率限制。
实例:
“`php
// 设置合理的UserAgent和请求延时函数
“`
6、伪造Referer:
方法:在爬虫类中设置合理的Referer,伪造请求来自其他网站,绕过Referer限制。
实例:
“`php
function setReferer($ch) {
$referers = array(
‘http://www.example.com’,
//…其他Referer值
);
$referer = $referers[array_rand($referers)];
curl_setopt($ch, CURLOPT_REFERER, $referer);
}
“`
相关问答FAQs
1、问:常见的反爬虫机制有哪些?
答:常见的反爬虫机制包括IP限制、用户代理限制、验证码、动态页面渲染、频率限制和Referer限制。
2、问:如何在PHP中实现反爬虫策略?
答:在PHP中实现反爬虫策略可以通过使用代理IP、设置合理的UserAgent、解析和处理验证码、使用无头浏览器、随机请求策略以及伪造Referer等方式来实现,这些方法可以单独使用也可以结合使用,以提高反爬效果。
下面是一个简单的介绍,列出了一些常见的PHP反爬虫策略:
| 策略编号 | 策略名称 | 描述 |
| 1 | UserAgent检测 | 验证请求头中的UserAgent,拒绝不符合浏览器特征的请求 |
| 2 | Referer检测 | 验证请求头中的Referer,只允许来自特定来源的请求 |
| 3 | IP限制 | 对请求的IP地址进行限制,如限制每个IP的请求频率或直接拒绝某些IP |
| 4 | 验证码机制 | 要求用户输入验证码以证明其不是自动化程序 |
| 5 | 登录限制 | 要求用户登录后才能访问某些页面,防止匿名爬虫访问 |
| 6 | 请求频率限制 | 对单个IP或用户在一定时间内的请求次数进行限制 |
| 7 | Cookie追踪 | 通过Cookie追踪用户行为,对行为异常的请求进行限制 |
| 8 | 数据混淆 | 对页面数据进行混淆,如使用JavaScript动态生成数据 |
| 9 | 伪静态页面 | 使用伪静态页面技术,使爬虫难以解析真实URL |
| 10 | 防护XSS攻击 | 防止爬虫通过XSS攻击获取数据 |
| 11 | 限制请求方法 | 只允许GET或POST请求,拒绝其他HTTP方法 |
| 12 | 请求头完整性验证 | 验证请求头的完整性,拒绝篡改过的请求 |
| 13 | 限制请求参数 | 对请求参数进行限制,如限制参数长度或类型 |
| 14 | 蜘蛛协议(robots.txt) | 制定robots.txt文件,规定哪些页面允许爬取,哪些页面禁止爬取 |
| 15 | 网站地图(sitemap.xml) | 提供网站地图,引导爬虫抓取重要页面,减少对其他页面的抓取压力 |
请注意,这些策略并非绝对有效,因为爬虫开发者可能会不断寻找绕过这些策略的方法,建议综合使用多种策略,以提高网站的反爬虫能力。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/716319.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。