


大数据和数据仓库是现代数据管理领域中两个至关重要但有所区别的概念,它们各自在数据存储、处理和分析方面发挥着不同的作用,并适用于不同的业务场景,具体如下:


1、定义与概念
大数据:指无法通过传统数据库工具在合理时间内进行捕捉、管理和处理的庞大数据集,这通常涉及到使用先进的计算框架,如Hadoop和Spark,来处理和分析数据集。
数据仓库:是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策,它侧重于数据的整合和时间序列分析。
2、技术架构与设计原理
大数据:利用并行处理和分布式系统来处理海量数据,常用的技术包括MapReduce编程模型和NoSQL数据库。
数据仓库:通常基于关系数据库管理系统(RDBMS),使用ER(实体关系)模型和维度建模技术来设计数据结构。
3、数据处理能力与应用场景
大数据:擅长处理半结构化和非结构化数据,常用于实时分析和处理大量快速变化的数据,如社交媒体数据和物联网设备数据。
数据仓库:主要用于执行复杂的查询和报表生成,支持商业智能(BI)和决策支持系统(DSS),适合处理结构化数据。
4、企业中的运用
大数据:帮助企业实时洞察市场和消费者行为,优化运营效率和创新服务。
数据仓库:为企业提供历史数据的深入分析,帮助制定长期策略和业务发展规划。
5、未来发展趋势
大数据:随着人工智能和机器学习技术的发展,预计大数据将更多地被用于预测分析和操作智能。
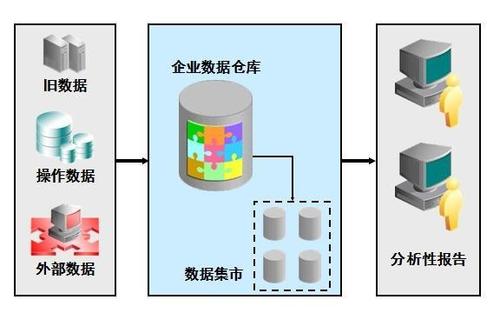
数据仓库:数据仓库可能会继续向云服务和实时数据处理方向发展,提高其灵活性和可访问性。
大数据和数据仓库虽然都是处理数据的工具,但它们在技术实现、数据处理能力及应用场景上有所不同,大数据强调对海量和多样类型数据的快速处理能力,而数据仓库则更专注于整合和历史数据分析,以支持决策制定过程,在选择适当的数据解决方案时,了解这些差异对于满足特定业务需求至关重要。
下面是一个简单的介绍,概述了大数据与数据仓库的相关概念和特点:
| 特性/概念 | 大数据 | 数据仓库 |
| 定义 | 指的是无法使用常规软件工具在合理时间内捕捉、管理和处理的大量数据集合 | 专门用于分析和查询的、面向主题的、集成的、稳定的、随时间变化的数据集合 |
| 数据类型 | 结构化、半结构化和非结构化数据 | 主要结构化数据 |
| 主要用途 | 数据挖掘、预测分析、复杂的数据处理和分析 | 支持管理决策、历史数据分析 |
| 技术支撑 | Hadoop、Spark、Flink等分布式处理框架 | Hive、传统数据库等,通常建立在分布式存储系统如HDFS上 |
| 数据组织 | 按照分布式文件系统进行存储和管理 | 按照主题组织,如客户、产品、销售等 |
| 数据处理 | 强调实时处理能力和大规模并行计算 | 强调高效的数据分析和查询 |
| 集成性 | 需要从多个数据源集成数据 | 必须集成来自多个异构数据源的数据 |
| 稳定性 | 数据可能频繁更新 | 数据通常是稳定的,不会频繁变更 |
| 时间维度 | 包含时间维度,可进行动态分析 | 包含时间维度,支持历史数据分析 |
| 优势 | 可以处理PB级别以上的数据 | 提供了专门针对复杂数据查询的优化 |
| 挑战 | 数据清洗、数据存储、数据处理 | 数据集成、数据模型设计、性能优化 |
| 典型工具 | Hadoop、Spark、HBase | Hive、传统数据库、数据仓库工具 |
| 应用场景 | 互联网搜索、日志分析、社交媒体分析 | 财务报告、销售预测、客户行为分析 |
这个介绍提供了大数据和数据仓库的简单对比,帮助理解两者之间的联系和区别,在实际应用中,大数据技术和数据仓库常常是相辅相成的,共同支撑起企业的数据分析和决策过程。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/712741.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复