


Hive是一个建立在Hadoop之上的数据仓库工具,它允许用户将结构化数据文件映射为数据库表,并执行SQL查询,下面将详细介绍Hive数据库的导入导出机制,以供用户在实际操作时作为参考:
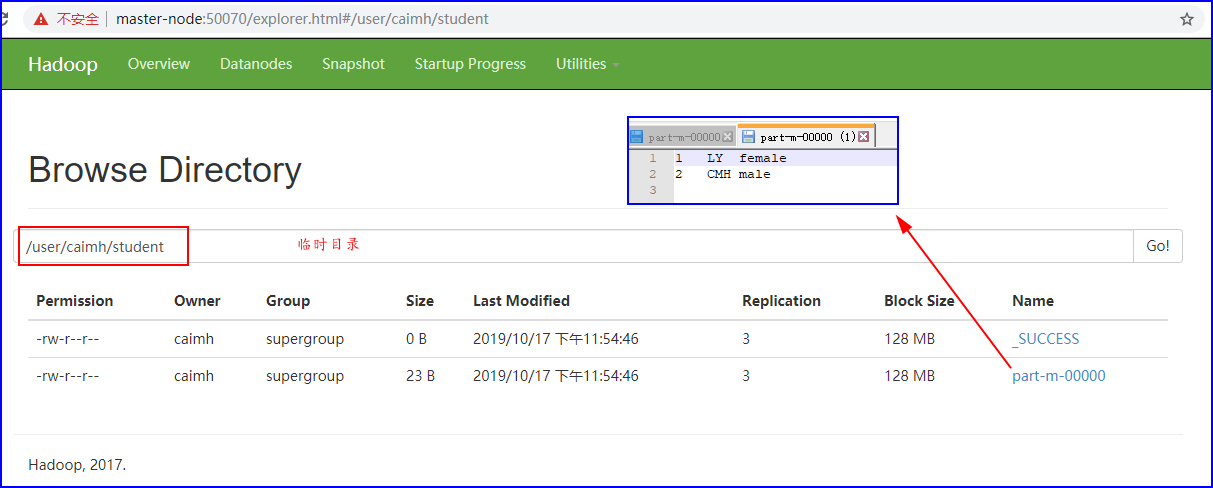

1、Hive数据导入方式
从本地文件系统导入数据到Hive表:可以使用LOAD DATA LOCAL INPATH命令将本地文件系统中的数据导入到Hive表中,若要导入一个名为studentno_data.txt的文件,存储路径为/home/training/zzy_scripts/studentno_data.txt,则相应的Hive命令如下:
从HDFS导入数据到Hive表:如果数据已经存储在HDFS上,可以使用LOAD DATA INPATH命令直接从HDFS导入数据到Hive表。
通过Sqoop从RDBMS导入到Hive表:Sqoop是一个工具,用于在Hadoop和关系型数据库之间传输数据,通过Sqoop可以将例如MySQL这样的关系型数据库中的数据导入到Hive表中,这个过程通常涉及到将数据从MySQL等数据库导出成一个CSV或者TSV文件,然后使用Sqoop将这些数据文件导入到Hive表中,具体操作可以参考相关文档《定时从大数据平台同步HIVE数据到Oracle》。
创建表的过程中从其他表导入:在创建新的Hive表时,可以通过AS SELECT语句从现有表中查询并插入数据到新表中,这种方式适合场景需要对数据进行转换或加工后再导入新表的情况。
2、Hive数据导出方式
Hive表导出到本地文件系统:可以使用INSERT OVERWRITE LOCAL DIRECTORY命令将Hive表中的数据导出到本地文件系统,若要把名为score的表中的数据导出到本地目录/export/servers/exporthive,则可以使用以下命令:
Hive表导出到HDFS:类似于导出到本地文件系统,使用INSERT OVERWRITE DIRECTORY命令可以将数据导出到HDFS上的指定目录。
通过Sqoop将Hive表导出到RDBMS:与导入相反,Sqoop也支持将Hive表中的数据导出到关系型数据库如MySQL,这通常用于数据整合、分析结果回写到业务数据库等场景。
3、考虑数据格式和类型兼容性
当从不同类型的系统导入导出数据时,必须确保数据的格式和类型兼容,在将数据导入到Hive表时,应确保CSV文件的字段与表的列类型相匹配,同样,在导出数据时,应考虑到目标系统的数据格式要求,如必要时进行适当的转换或加工。
4、考虑数据量大的处理策略
对于大量数据的导入导出,需要考虑到操作可能对Hadoop集群的性能影响,可以采用分区、压缩等策略来优化性能和存储,合理安排导入导出的时间和方式,避免高峰时段执行,可以有效减轻对集群的压力。
Hive数据库提供了丰富的数据导入导出方法,包括从本地文件系统、HDFS、其他Hive表以及通过Sqoop从RDBMS系统导入数据,以及将数据导出到本地文件系统、HDFS和RDBMS系统,每种方法都有其适用的场景和特点,用户在选择时应考虑数据量、数据处理需求以及系统环境等因素,通过合理利用这些功能,可以高效地管理和分析存储在Hadoop生态系统中的大数据。
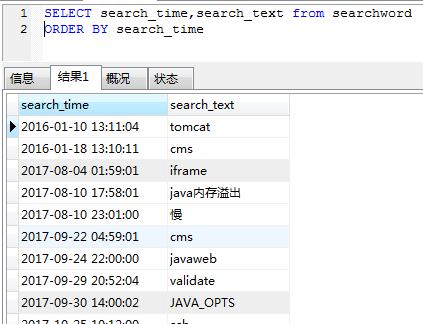
下面是一个关于Hive数据库导入导出操作的介绍:
| 操作类别 | 命令格式 | 描述 | 适用场景 |
| 导入数据 | |||
| 本地文件导入非分区表 | LOAD DATA LOCAL INPATH '/path/to/local/file' INTO TABLE database_name.table_name; | 将本地文件系统的数据导入到Hive非分区表中 | 数据文件在本地,且不需要分区管理 |
| 本地文件导入分区表 | LOAD DATA LOCAL INPATH '/path/to/local/file' OVERWRITE INTO TABLE database_name.table_name PARTITION (partition_column='value'); | 将本地文件系统数据导入到Hive分区表中,并覆盖旧数据 | 需要按分区导入数据,并覆盖旧数据 |
| HDFS文件导入 | LOAD DATA INPATH '/path/to/hdfs/file' INTO TABLE database_name.table_name; | 将HDFS上的数据文件导入到Hive表中 | 数据已经存储在HDFS上 |
| 通过查询导入 | INSERT INTO TABLE database_name.table_name SELECT * FROM another_database.another_table; | 通过Hive查询语句将查询结果导入到表中 | 需要从其他表中选择数据导入 |
| 创建表时导入 | CREATE TABLE database_name.table_name AS SELECT * FROM another_database.another_table; | 在创建表的同时将查询结果作为表数据 | 需要创建新表并导入数据 |
| 导出数据 | |||
| 导出数据到本地 | INSERT OVERWRITE LOCAL DIRECTORY '/path/to/local/directory' SELECT * FROM database_name.table_name; | 将Hive表中的数据导出到本地文件系统 | 需要将数据下载到本地进行分析或备份 |
| 导出数据到HDFS | INSERT OVERWRITE DIRECTORY '/path/to/hdfs/directory' SELECT * FROM database_name.table_name; | 将Hive表中的数据导出到HDFS | 需要将数据存储在HDFS上,或进一步处理 |
| 通过Hive命令导出 | dfs get /path/to/hive/data/* /path/to/local/; | 使用Hadoop命令直接从Hive的数据目录导出到本地 | 了解Hive数据在HDFS上的存储路径,手动导出 |
| 使用Sqoop导出 | sqoop export ... | 使用Sqoop工具将Hive中的数据导出到关系数据库 | 需要将数据迁移到关系数据库或其他系统 |
请注意,上述命令中的路径和表名需要根据实际情况替换,这些命令提供了基本的导入导出操作方法,但实际使用中可能还需要考虑数据格式、压缩方式、性能优化等因素。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/711719.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复