



数据收集与预处理
1. 数据采集技术
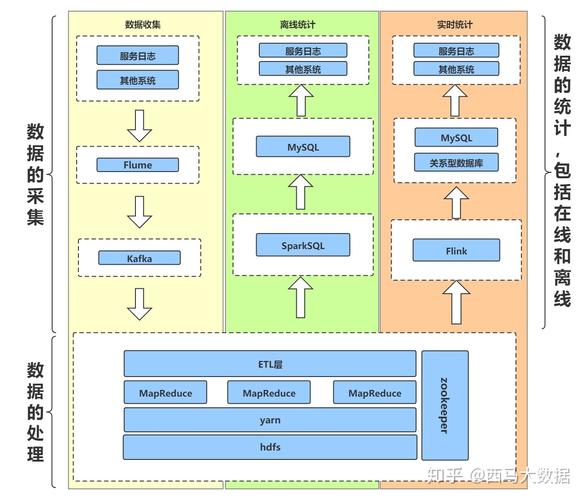
日志收集:使用Flume、Logstash等工具进行实时或批量的日志数据收集。
网络爬虫:利用Scrapy、Nutch等框架抓取互联网数据。
设备采集:通过传感器、IoT设备直接采集数据。
2. 数据预处理
数据清洗:去除重复、错误和无关的数据。
数据转换:将数据转换为统一的格式或结构,如使用ETL工具(Apache NiFi、Talend)。
数据集成:合并来自不同源的数据,解决数据冗余和不一致问题。
数据存储与管理
1. 分布式文件系统
HDFS:Hadoop Distributed File System,适用于大规模数据集的存储。
GlusterFS:可扩展的网络附着存储。
2. NoSQL数据库
键值存储:如Redis、DynamoDB,适合高速读写场景。
文档数据库:如MongoDB,存储JSON等半结构化数据。
列式数据库:如Cassandra和HBase,适合宽表和高吞吐量的场景。
3. 数据仓库技术
传统数据仓库:如Teradata、Oracle。
云数据仓库:如Amazon Redshift、Google BigQuery。
数据处理与分析
1. 批处理框架
Hadoop MapReduce:用于大规模数据集的并行处理。
Apache Spark:内存计算框架,提高数据处理速度。
2. 流处理框架
Apache Storm:实时数据处理。
Apache Flink:流处理和批处理结合的高性能框架。
3. 查询分析工具
Hive:提供类似SQL的查询接口。
Pig:简化MapReduce编程的高级脚本语言。
数据安全与治理
1. 数据加密
静态加密:保护存储中的数据。
动态加密:保护传输中的数据。
2. 数据备份与恢复
定期备份:确保数据的持久性和一致性。
灾难恢复策略:应对系统故障和数据丢失。
3. 数据质量管理
质量监控:持续监测数据的准确性和完整性。
数据治理:制定标准和政策来管理数据的质量、可用性和安全性。
大数据平台与生态
1. 大数据操作系统
YARN:Yet Another Resource Negotiator,资源管理系统。
Kubernetes:容器编排系统,用于自动化部署、扩展和管理容器化应用。
2. 大数据生态系统
Apache Kafka:高吞吐量的分布式消息系统,用于构建实时数据管道和应用。
Apache Zeppelin:基于Web的笔记本,用于数据驱动的分析。
涵盖了大数据技术架构的基础层的关键技术和组件,为构建和优化大数据解决方案提供了详细的技术参考。
下面是一个简化的介绍,描述大数据技术构架的基础层及其包含的基础技术:
| 基础层分类 | 子分类 | 技术内容 |
| 硬件设施 | CPU硬件、芯片、存储设备等 | |
| 软件设施 | 云平台 | 谷歌大数据平台、百度智能云平台等 |
| 大数据平台 | Hadoop、Spark等 | |
| 数据服务 | 通用数据 | 第三方数据提供企业,如海天瑞声技术公司 |
| 行业数据 | Crowd Flower等数据服务公司 | |
| 数据存储 | 分布式存储 | HDFS(三份副本策略、Erasure Code技术) |
| NoSQL数据库 | Hyperbase、Hbase等 | |
| 图形数据库 | Titan等 | |
| 数据计算 | 分布式计算 | MapReduce、YARN等 |
| 实时计算 | Flink、Spark Streaming等 | |
| 作业调度 | Oozie、Airflow等 | |
| 架构安全 | 安全协议、加密技术等 | |
| 运维管理 | 监控系统、日志管理、自动化运维工具等 | |
| 数据权限 | 访问控制、角色权限管理、数据加密等 | |
| 数据查询 | 多维度秒级检索查询(索引支持) | |
| 应用层框架 | 支持各类结构化、半结构化、非结构化数据的处理和分析 |
请注意,这个介绍是根据提供的参考信息整理的,每个子分类下可能还有更多的技术细节和不同的实现方式,这里仅提供一个概览性的描述。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/710117.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复