


Python是一种非常强大的编程语言,它提供了许多用于创建和操作数据的工具,在这篇文章中,我们将讨论如何使用Python来创建数据。
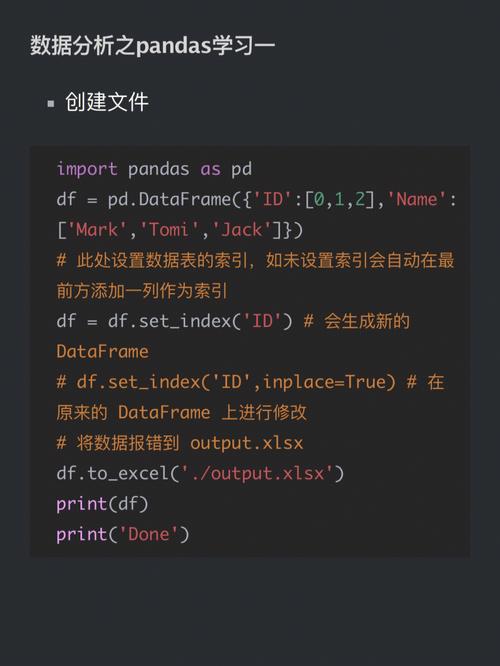

我们需要了解Python中的数据类型,Python有几种内置的数据类型,包括整数、浮点数、字符串、列表、元组、集合和字典,这些数据类型可以用于存储和操作数据。
如果我们想要创建一个包含整数的列表,我们可以这样做:
numbers = [1, 2, 3, 4, 5]
在这个例子中,我们创建了一个名为numbers的列表,其中包含了五个整数。
我们也可以使用Python的内置函数来生成数据,如果我们想要生成一个包含前10个整数的列表,我们可以使用range()函数:
numbers = list(range(10))
在这个例子中,range(10)生成了一个包含前10个整数的序列,然后我们使用list()函数将其转换为列表。
除了内置的数据类型和函数,Python还有许多库可以用来创建和操作数据。numpy和pandas是两个非常流行的数据处理库。
numpy是一个用于处理数组和矩阵的库,我们可以使用numpy来创建和操作大型数据集,我们可以使用numpy.array()函数来创建一个数组:
import numpy as np numbers = np.array([1, 2, 3, 4, 5])
在这个例子中,我们首先导入了numpy库,然后使用np.array()函数创建了一个数组。
pandas是一个用于处理表格数据的库,我们可以使用pandas来创建和操作数据框(DataFrame),我们可以使用pandas.DataFrame()函数来创建一个数据框:
import pandas as pd
data = {'Name': ['Tom', 'Nick', 'John'], 'Age': [20, 21, 19]}
df = pd.DataFrame(data) 在这个例子中,我们首先导入了pandas库,然后使用pd.DataFrame()函数创建了一个数据框。
就是如何使用Python来创建数据的一些基本方法,Python的功能远不止于此,我们还可以使用Python来进行数据分析、机器学习等复杂的任务。
FAQs
Q1: Python有哪些内置的数据类型?
A1: Python有几种内置的数据类型,包括整数、浮点数、字符串、列表、元组、集合和字典。
Q2:numpy和pandas有什么区别?
A2:numpy是一个用于处理数组和矩阵的库,而pandas是一个用于处理表格数据的库,两者都可以用于创建和操作数据,但numpy更适合处理大型数据集,而pandas更适合处理数据框。
如果您希望用Python来创建一个简单的数据介绍,并且假设您希望将这个介绍用于数据分析和处理(例如使用Pandas库),以下是一个简单的例子。
您需要安装Pandas库(如果尚未安装):
pip install pandas
使用以下Python代码创建一个示例介绍:
import pandas as pd
创建数据字典
data = {
'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [25, 30, 35, 40],
'性别': ['男', '男', '女', '女'],
'工资': [8000, 10000, 12000, 15000]
}
创建DataFrame
df = pd.DataFrame(data)
打印介绍
print(df) 上述代码创建了一个包含四个人信息的简单介绍,包括他们的姓名、年龄、性别和工资,Pandas的DataFrame对象df将这个数据以介绍形式展现。
当您运行这段代码时,输出应该像这样:
姓名 年龄 性别 工资 0 张三 25 男 8000 1 李四 30 男 10000 2 王五 35 女 12000 3 赵六 40 女 15000
DataFrame可以用来执行各种复杂的数据操作,包括数据筛选、转换、聚合等,如果您需要将这个介绍保存为CSV或Excel文件,可以使用如下命令:
保存为CSV文件
df.to_csv('data.csv', index=False, encoding='utf8sig')
保存为Excel文件
df.to_excel('data.xlsx', index=False) 请注意,这里使用index=False是为了在保存时不包括默认的索引列。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/710053.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复