


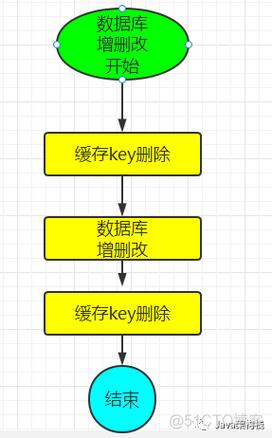
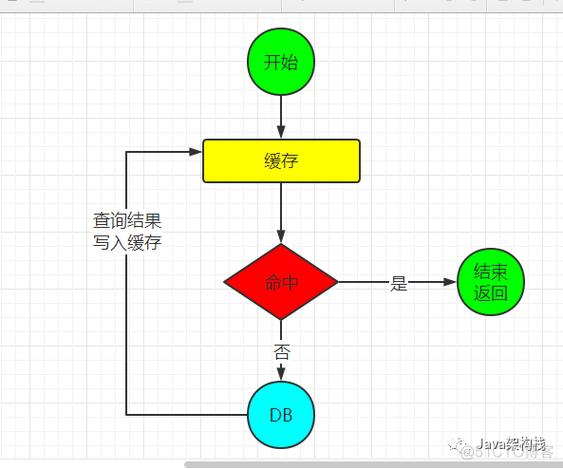
分布式缓存和缓存设置

分布式缓存简介
分布式缓存是一个在多台服务器之间共享的缓存系统,用于提高数据访问速度、减少数据库负载以及实现高可用性,它通过将数据存储在内存中,使得应用程序可以快速读取数据,从而提升整体性能。
常见的分布式缓存系统
Memcached
Redis
Hazelcast
Ehcache
Couchbase
缓存设置步骤
1. 确定需求
需要明确缓存的需求,包括缓存的数据类型、大小、访问频率等,这将帮助你选择合适的缓存系统和配置。
2. 选择缓存系统
根据需求选择一个合适的缓存系统,如果你需要支持复杂的数据结构,如列表和集合,那么Redis可能是一个好选择。
3. 安装和配置
安装所选的缓存系统,并配置其网络、内存、持久化等相关设置。
4. 集成到应用
在你的应用程序中添加代码,以使用缓存系统,这通常涉及添加新的库或框架,并在需要缓存的地方修改代码。
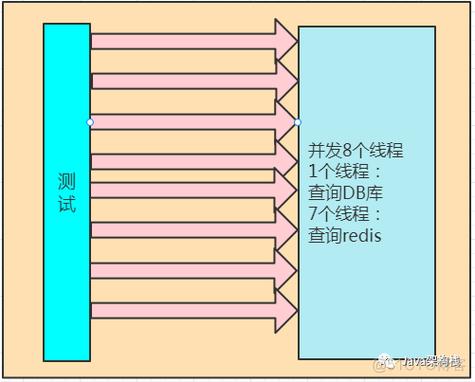
5. 测试
确保缓存系统正常工作,并且你的应用程序能够正确使用它,这可能包括性能测试和故障恢复测试。
6. 监控和维护
一旦缓存系统投入使用,你需要监控其性能和健康状况,并根据需要进行维护。
缓存设置示例(以Redis为例)
以下是一个使用Redis作为分布式缓存的简单Java示例:
import redis.clients.jedis.Jedis;
public class CacheExample {
private Jedis jedis;
public CacheExample(String host, int port) {
this.jedis = new Jedis(host, port);
}
public void set(String key, String value) {
jedis.set(key, value);
}
public String get(String key) {
return jedis.get(key);
}
} 在这个示例中,我们创建了一个CacheExample类,它使用Jedis库连接到Redis服务器,并提供了set和get方法来存储和检索数据。
下面是一个介绍,概述了分布式缓存与本地缓存的特点、设置及优缺点。
| 特性 | 本地缓存 | 分布式缓存 |
| 缓存位置 | 内存,单机 | 分布在多台服务器上的内存 |
| 数据共享 | 不可共享,仅限当前进程 | 可共享,支持多进程/多服务器 |
| 技术异构性 | 通常与特定语言或平台绑定 | 语言无关,支持多种开发环境 |
| 扩展性 | 固定大小,不易扩展 | 易于水平扩展,可增加节点以提高缓存容量 |
| 持久化机制 | 通常没有,进程停止数据丢失 | 支持数据持久化,即使节点失效数据不丢失 |
| 性能 | 非常高,无网络开销 | 较高,但存在网络通信开销 |
| 缓存命中率 | 高 | 依赖于网络延迟和复制策略,通常稍低 |
| 设置复杂性 | 简单,易于集成 | 复杂,需要配置网络、同步机制等 |
| 优点 | + 性能极高 + 无需网络通信 | + 支持多应用/多服务器共享数据 + 可扩展性好 + 数据持久化 |
| 缺点 | 数据不持久化 缓存数据无法共享 | 网络延迟影响性能 管理复杂度较高 |
分布式缓存设置示例:
1、选择缓存技术:如Redis、Memcached、Cassandra等。
2、配置缓存节点:设置网络中的多台服务器作为缓存节点。
3、数据复制和分区:根据需要配置数据复制和分区策略,以实现负载均衡和冗余。
4、一致性哈希算法:使用一致性哈希算法,确保在节点增减时最小化数据迁移。
5、缓存策略:配置缓存过期时间、数据淘汰机制等。
6、缓存预热:提前将热点数据加载到缓存中,提高缓存命中率。
7、监控和维护:定期监控缓存节点的健康状态,进行性能调优和故障处理。
通过这个介绍,可以直观地了解分布式缓存与本地缓存之间的差异以及设置分布式缓存时需要考虑的要点。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/709227.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复