


1、数据收集:大数据的第一步是收集数据,这可能来自各种来源,包括社交媒体、传感器、日志文件、数据库等。

2、数据清洗:收集的数据可能包含错误、重复或不完整的信息,因此需要进行数据清洗,以确保数据的准确性和一致性。
3、数据存储:大数据需要存储在适当的位置,以便进行分析,这可能包括使用数据库、数据湖或其他类型的数据存储解决方案。
4、数据分析:这是大数据的核心部分,包括使用统计方法、机器学习算法等对数据进行深入分析,以发现模式、趋势和关联。
5、数据可视化:将数据分析的结果以图形或图表的形式展示出来,使得非专业人士也能够理解和利用这些数据。
6、数据安全:保护数据的安全是非常重要的,包括防止数据丢失、被盗或被篡改。
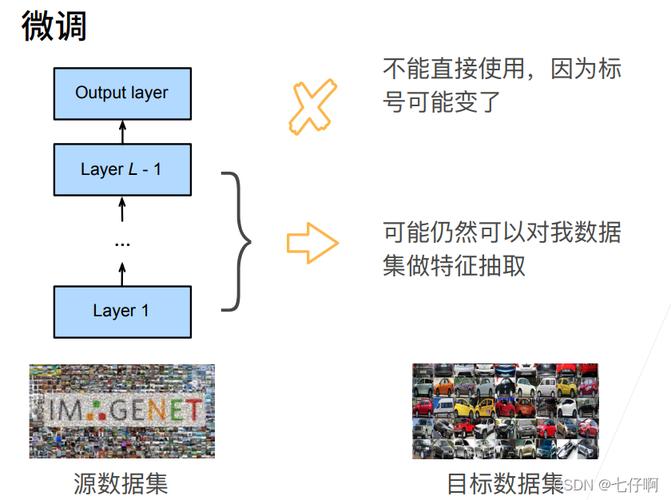
大模型微调需要的数据有要求吗?
是的,大模型微调需要的数据有一定的要求,以下是一些主要的要求:
1、数据质量:数据必须是高质量的,即准确、完整、一致和可用的,低质量的数据可能会导致模型的性能下降。
2、数据量:大模型通常需要大量的数据来进行训练和微调,这是因为大模型有更多的参数需要学习,因此需要更多的数据来避免过拟合。
3、数据多样性:数据应该尽可能覆盖所有可能的情况,以便模型能够学习到各种各样的模式和关系。
4、数据标注:对于监督学习任务,数据需要有正确的标签,标签的质量直接影响模型的性能。
5、数据分布:训练数据和测试数据的分布应该尽可能相似,否则模型可能会在实际应用中表现不佳。
以下是一个简单的表格,归纳了上述内容:
| 主题 | 描述 |
| 数据收集 | 从各种来源收集数据 |
| 数据清洗 | 确保数据的准确性和一致性 |
| 数据存储 | 使用适当的解决方案存储数据 |
| 数据分析 | 使用统计方法和机器学习算法分析数据 |
| 数据可视化 | 将分析结果以图形或图表的形式展示 |
| 数据安全 | 保护数据的安全 |
| 数据质量 | 数据必须是高质量的 |
| 数据量 | 大模型需要大量的数据 |
| 数据多样性 | 数据应覆盖所有可能的情况 |
| 数据标注 | 对于监督学习任务,数据需要有正确的标签 |
| 数据分布 | 训练数据和测试数据的分布应相似 |
下面是一个介绍,概述了大模型微调对数据的主要要求:
| 数据要求 | 描述 |
| 数据质量 | 微调过程中至关重要,模型会学习数据的分布,如果数据质量低,模型输出也可能质量低。 |
| 数据多样性 | 输入数据的多样性对于防止模型过拟合和增强其泛化能力至关重要,模型应学习不同的数据模式而非仅仅记忆。 |
| 真实性 | 使用领域内或生活中的真实数据,而非由AI生成的数据,确保模型学习到真实世界的数据分布。 |
| 数据量 | 虽然预训练模型已经从大量数据中学习,但适量的微调数据仍然重要,不过质量往往比数量更重要。 |
| 数据标注 | 标注数据的准确性直接影响微调效果,应确保数据标注正确且一致。 |
| 数据构造 | 构建用于微调的数据集时,应考虑采用自动化方法筛选和构造数据,例如使用Nuggets等技术。 |
| 特定任务适应性 | 数据应与特定任务紧密相关,以指导模型在特定领域或任务上表现得更好。 |
| 效率和成本 | 在保证效果的前提下,应尽量减小数据规模以降低存储和处理成本,提高微调效率。 |
这个介绍总结了大模型微调过程中对数据的一些关键要求,旨在帮助研究人员和实践者更有效地进行微调工作。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/708716.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复