

在计算机科学中,持久化是指数据在存储介质上的保存状态,即使在系统断电或重启后,这些数据也能被重新访问和利用,持久化存储是确保数据长期保存的关键机制,它允许数据跨程序运行实例或设备进行持久保存。


持久化存储的类型
持久化存储可以大致分为以下几种类型:
1、文件系统存储:这是最传统的持久化手段,数据以文件的形式保存在硬盘或其他存储媒体上。
2、关系型数据库存储:如MySQL、Oracle等,它们使用结构化查询语言(SQL)来管理和查询数据。
3、非关系型数据库存储:如MongoDB、Redis等,它们提供了不同于传统关系型数据库的数据存储与查询方式。
4、键值存储系统:如DynamoDB、Riak等,它们通过键值对的方式高效地存取数据。
5、对象存储系统:如Amazon S3、Google Cloud Storage等,它们管理的是对象而非文件或块,每个对象包含数据、元数据和唯一标识符。
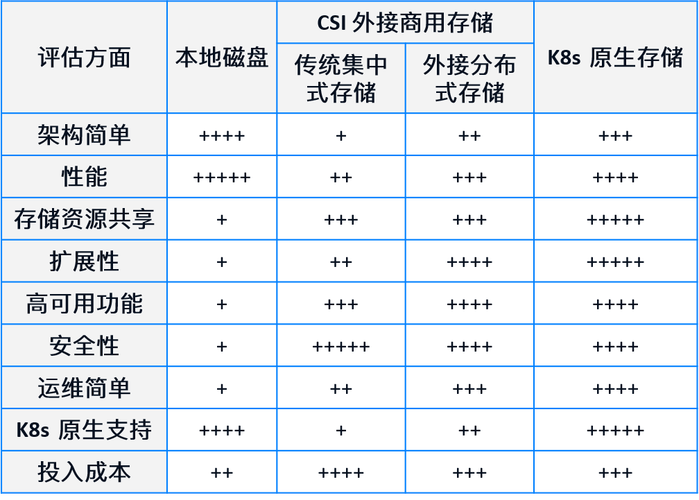
6、分布式文件系统:如HDFS、Ceph等,它们设计用于在多台机器上存储大量数据。
7、时间序列数据库:如InfluxDB、Prometheus等,专门用于存储和查询时间序列数据。
持久化存储的考量因素
在选择持久化存储方案时,需要考虑多个因素:
数据的结构和格式:结构化数据可能更适合关系型数据库,而半结构化或非结构化数据可能更适合NoSQL数据库或文件系统。
读写性能:不同的存储系统在读写性能上有显著差异,需要根据应用需求选择。
可扩展性:数据量的增长可能导致存储需求的变化,所选存储系统应能轻松扩展。
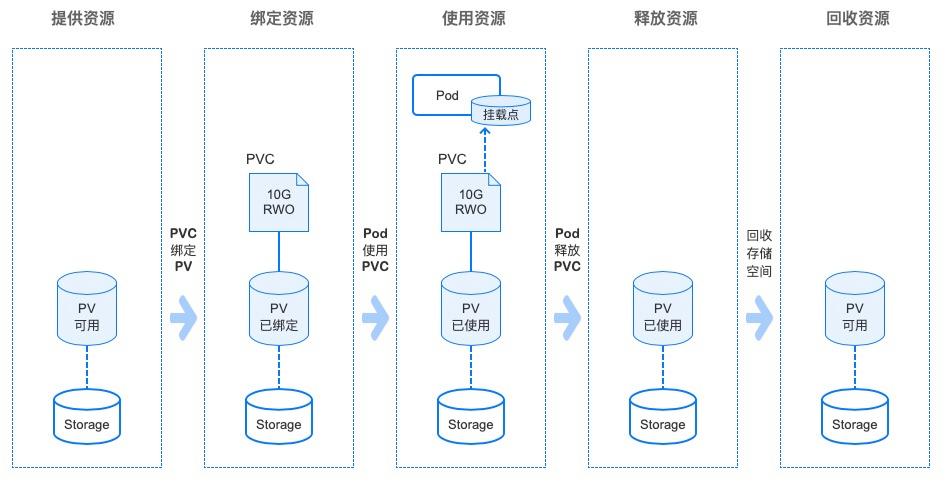
一致性与可用性:在分布式系统中,CAP定理指出一致性、可用性和分区容忍性三者不可兼得,需根据业务需求做出取舍。
成本:不同存储解决方案的成本差异较大,包括硬件成本、运营成本和维护成本等。
持久化存储的挑战
尽管持久化存储为数据的长期保存提供了解决方案,但也存在一些挑战:
数据一致性:在分布式系统中确保数据一致性是一项挑战。
数据安全:防止数据丢失、损坏和未授权访问需要严格的安全措施。
备份与恢复:有效的备份策略和灾难恢复计划对于保护数据至关重要。
相关问答FAQs
Q1: 如何选择合适的持久化存储方案?
A1: 选择合适的持久化存储方案应考虑数据类型、性能需求、预算限制、系统的可扩展性以及数据一致性和安全性要求,对于需要高速读写和严格一致性的金融交易数据,可能适合使用关系型数据库;而对于大规模日志数据,则可能更适合使用时间序列数据库或分布式文件系统。
Q2: 持久化存储中的CAP定理是什么?
A2: CAP定理,也称为布鲁尔定理,它指出在一个分布式数据存储系统中,Consistency(一致性)、Availability(可用性)和Partition Tolerance(分区容忍性)这三者不可能同时满足,在设计分布式系统时,需要在这三个属性中做出权衡,一个系统可能选择牺牲一定的一致性来保证高可用性和分区容忍性,如许多NoSQL数据库所做的那样。
| 场景 | 技术 | 描述 | 优点 | 缺点 |
| Vue3前端应用 | 自定义介绍列持久化 | 用户自定义介绍列(如顺序、隐藏、宽度)并通过后端存储 | 用户个性化设置可持久化 每个用户可拥有不同视图 | 需要后端支持 前后端交互增加复杂度 |
| Unity游戏开发 | PlayerPrefs | 使用Unity内置的PlayerPrefs进行简单数据存储 | API简单易用 支持基本数据类型 | 存储容量有限 不适合大量或复杂数据存储 |
| Vue.js状态管理 | Pinia持久化插件 | 通过Pinia插件实现状态持久化 | 集成简单 可配置数据持久化路径 | 依赖第三方插件 可能影响性能 |
| Kubernetes存储 | OpenEBS | OpenEBS作为Kubernetes的开源存储解决方案 | 支持多种存储引擎 高可用性和数据管理功能 | 需要一定的学习和配置 可能引入额外的复杂性 |
| Kubernetes应用 | Elasticsearch持久化 | 在Kubernetes上搭建Elasticsearch高可用集群并持久化存储数据 | 数据高可用 易于扩展 | 集群搭建复杂 资源消耗较大 |
这个介绍概括了不同应用场景下,使用各种技术实现数据持久化的特点,包括它们的优点和缺点,开发者可以根据具体需求选择合适的技术方案。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/708708.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复