


Parquet格式与MapReduce的集成
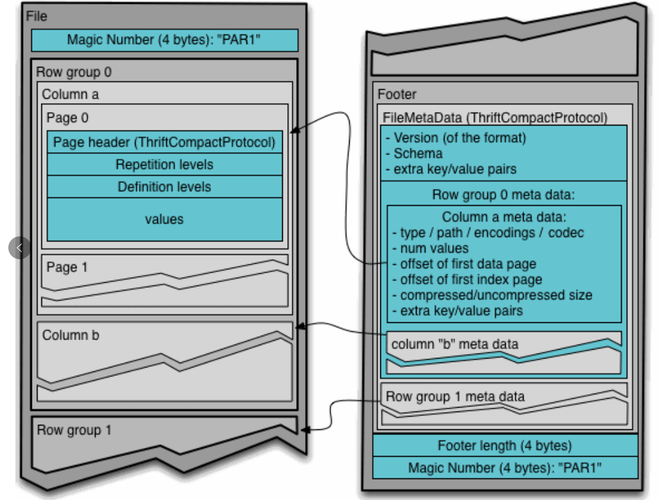

Parquet是一种列式存储文件格式,它提供了高效的压缩和编码方案,特别适用于大数据处理场景,在Hadoop生态系统中,Parquet经常与MapReduce框架结合使用,以实现对大规模数据集的高效处理,本文将详细介绍Parquet格式及其与MapReduce的集成方式。
1. Parquet格式简介
Parquet是一种自描述的列式存储文件格式,支持多种编程语言和数据处理框架,它的主要特点如下:
列式存储:Parquet按列而非行存储数据,这使得读取特定列时无需加载整个数据集,从而提高了查询性能。
嵌套结构:Parquet支持嵌套的数据结构,如JSON、Avro等,这使得它可以灵活地表示复杂的数据模型。
压缩和编码:Parquet提供了多种压缩算法(如Snappy、Gzip等)和编码方案(如字典编码、游程编码等),以减少磁盘空间占用和提高查询性能。
兼容性:Parquet支持多种数据处理框架,如Hadoop、Spark、Hive等,这使得它可以方便地与其他工具集成。

2. MapReduce简介
MapReduce是Hadoop生态系统中的一种分布式计算框架,它将计算任务分为两个阶段:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个数据块,每个数据块由一个Map任务处理并生成中间结果,在Reduce阶段,中间结果根据键值进行聚合,生成最终结果。
3. Parquet与MapReduce的集成
要将Parquet与MapReduce集成,需要使用Parquet的Java API或Hadoop的Parquet库,以下是一个简单的示例,展示了如何使用Parquet与MapReduce处理数据:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.ParquetInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.parquet.hadoop.ParquetReader;
import org.apache.parquet.hadoop.example.GroupWriteSupport;
public class ParquetMapReduceExample {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Parquet MapReduce Example");
job.setJarByClass(ParquetMapReduceExample.class);
job.setInputFormatClass(ParquetInputFormat.class);
ParquetInputFormat.addInputPath(job, new Path(args[0]));
job.setMapperClass(ParquetMapper.class);
job.setReducerClass(ParquetReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(ParquetReader.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 在这个示例中,我们首先配置了一个MapReduce作业,然后设置了输入格式为ParquetInputFormat,并指定了输入路径,我们设置了Mapper和Reducer类,以及输出键值类型,我们指定了输出路径,并启动了作业。
4. 优势与局限
将Parquet与MapReduce集成的优势主要体现在以下几个方面:

高效的列式存储:由于Parquet是列式存储格式,因此在执行涉及特定列的查询时,可以显著提高查询性能。
灵活的数据模型:Parquet支持嵌套的数据结构,这使得它可以方便地处理复杂的数据模型。
压缩和编码:Parquet提供了多种压缩算法和编码方案,有助于减少磁盘空间占用和提高查询性能。
广泛的兼容性:Parquet支持多种数据处理框架,这使得它可以方便地与其他工具集成。
Parquet与MapReduce的集成也存在一些局限性:
学习成本:对于不熟悉Parquet和MapReduce的用户来说,学习和掌握这种集成方式可能需要一定的时间和精力。
性能调优:虽然Parquet提供了许多优化选项,但要达到最佳性能可能需要进行详细的性能调优。
5. 应用场景
Parquet与MapReduce的集成适用于以下几种场景:
大数据分析:在处理大规模数据集时,可以利用Parquet的列式存储和压缩特性来提高查询性能和降低磁盘空间占用。
数据仓库:在构建数据仓库时,可以使用Parquet作为存储格式,以便在多个数据处理框架之间共享数据。
数据挖掘:在数据挖掘任务中,可以利用Parquet的嵌套数据结构和高效查询性能来处理复杂的数据模型和提取有价值的信息。
6. 归纳
Parquet与MapReduce的集成为处理大规模数据集提供了一种高效的解决方案,通过利用Parquet的列式存储、压缩和编码特性,以及MapReduce的分布式计算能力,可以实现高性能的数据处理任务,这种集成方式也存在一定的学习成本和性能调优挑战,在选择使用Parquet与MapReduce集成时,需要充分了解其优势和局限,并根据实际需求进行权衡。
下面是一个关于Parquet格式在MapReduce中的关键信息的介绍:
| 特性/组件 | 描述 |
| Parquet Format | |
| 文件格式 | 一种列式存储格式,适用于Hadoop生态系统,支持多种数据处理框架(如MapReduce、Impala、Spark等) |
| 设计目的 | 提供高效、紧凑的数据存储,支持快速的数据查询和分析 |
| 适用场景 | 大规模数据处理、数据仓库、交互式查询 |
| 在MapReduce中的使用 | |
| 数据存储 | 适用于MapReduce作业的输入和输出,特别是对于复杂的嵌套数据结构 |
| 性能优化 | 通过列式存储减少I/O操作,只读取需要的列数据 |
| 压缩 | 支持多种压缩编码(如Snappy、GZIP),减少存储空间和I/O带宽消耗 |
| 读写效率 | 支持高效的数据读写,尤其适合于MapReduce的shuffle阶段 |
| 关键特性 | |
| 列式存储 | 数据按列存储,有利于分析型查询,尤其是在处理宽表时 |
| 嵌套数据支持 | 支持复杂数据类型(如嵌套结构、数组、映射)的存储 |
| 通用性 | 兼容多种数据处理工具和查询引擎 |
| 可扩展性 | 支持自定义的数据类型和编码方式 |
| 兼容性 | |
| 数据模型 | 兼容多种语言的数据模型(如Java、Python等) |
| 框架支持 | 与MapReduce、Spark、Impala、Hive等框架兼容 |
| 版本控制 | 支持版本化,确保数据的长期可访问性 |
| 优化选项 | |
| 列压缩 | 可以为每列选择不同的压缩编码,以优化存储和性能 |
| 数据分区 | 支持数据分区,便于高效的数据访问和管理 |
| 数据索引 | 支持索引,有助于快速定位数据 |
请注意,这个介绍提供了一个概览,具体的使用和配置可能根据实际的应用场景和需求有所不同。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/707654.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复