


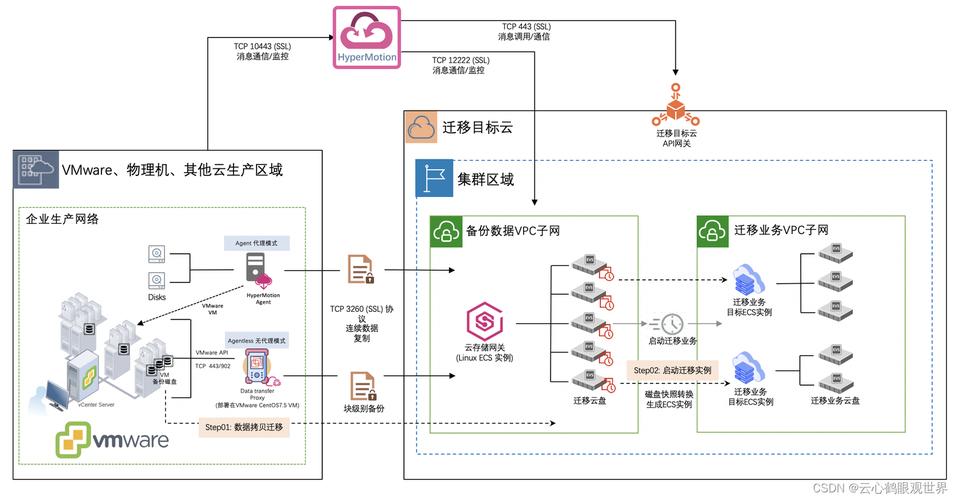
Kafka数据迁移

简介
在现代的云计算时代,越来越多的公司选择将他们的服务迁移到云端,Apache Kafka作为一个流行的分布式流处理平台,其数据的迁移也需要特别的关注和策略,本文将提供一个详细的,介绍如何将Kafka数据从本地服务器迁移到云端。
迁移前的准备工作
2.1 评估现有系统
数据量估算: 测量现有的Kafka集群的数据大小。
性能指标分析: 收集系统的延迟和吞吐量数据。
硬件资源调查: 记录当前使用的硬件配置。
2.2 选择云服务提供商
成本效益分析: 比较不同云服务商的价格和服务。
兼容性检查: 确保所选云平台支持Kafka版本和配置。
安全性评估: 考虑数据安全和合规性需求。
2.3 设计迁移策略
直接迁移vs逐步迁移: 决定是一次性迁移还是分阶段进行。
备份与恢复策略: 制定数据备份和灾难恢复计划。
测试计划: 准备迁移后的测试流程以验证数据完整性和系统性能。
迁移执行
3.1 设置云环境
创建虚拟机: 在云端创建必要的虚拟机实例。
网络配置: 配置网络以确保良好的性能和安全。
存储解决方案: 选择合适的云存储服务并配置。
3.2 数据迁移
使用工具迁移: 利用如MirrorMaker等工具同步数据。
手动迁移: 手动复制数据文件(适用于小数据集)。
验证数据一致性: 检查源集群和目标集群的数据一致性。
3.3 应用迁移
更新配置文件: 修改Kafka和相关应用的配置以指向新集群。
服务重启: 逐步重启服务,减少停机时间。
监控与调优: 监视新环境的性能并进行必要的优化。
迁移后的操作
4.1 性能监控
实时监控: 使用云服务提供的监控工具。
日志分析: 定期检查日志以发现潜在问题。
4.2 维护与更新
软件更新: 定期更新Kafka和相关软件以修补安全漏洞。
硬件扩展: 根据需要调整虚拟机规格和存储容量。
4.3 反馈与改进
用户反馈: 收集用户对新系统的反馈。
持续改进: 根据反馈调整系统配置和架构。
通过上述步骤的详细规划和执行,Kafka数据可以成功地从本地服务器迁移到云端,重要的是要确保在整个过程中保持数据的完整性和系统的高可用性,同时优化云环境以满足业务需求和预期的性能标准。
以下是一个关于“服务器迁移到云方案 Kafka数据迁移概述”的介绍:
| 序号 | 迁移环节 | 工具/方法 | 说明/备注 |
| 1 | 迁移前准备 | 制定数据迁移技术方案、应急预案及回切方案 | 明确迁移步骤、执行人、确认人,确保数据安全合规,评估迁移时长及割接数据同步窗口 |
| 2 | Kafka数据导出 | Kafka Connect S3 Source Connector | 将源MSK集群的数据导出到S3存储桶,应对网络不连通或账号隔离场景 |
| 3 | 数据传输 | S3存储桶 | 数据中转,便于在不同集群或账号之间传输数据 |
| 4 | Kafka数据导入 | Kafka Connect S3 Sink Connector | 将S3存储桶中的数据导入到目标MSK集群 |
| 5 | 迁移后校验 | 对比源、目标集群数据,确保数据一致性 | 执行迁移后校验工作,确认数据无误 |
| 6 | 简化操作 | Docker搭建Kafka Connect、自动化Shell脚本 | 提供开箱即用的解决方案,简化用户操作 |
| 7 | 集群化部署 | Kubernetes/Amazon MSK Connect | 适用于大规模数据同步和迁移,提高稳定性和健壮性 |
| 8 | 服务器资源搭配 | 参照现有物理服务器资源,选择合适的云服务器配置 | 避免资源浪费,控制成本,根据业务需求调整服务器配置 |
| 9 | 业务优化 | 重新构建云服务器应用程序 | 充分发挥云服务器功能,提高性能,控制成本,将解决方案开源或全面云化 |
这个介绍概述了服务器迁移到云的过程中,涉及Kafka数据迁移的主要环节、工具/方法以及相应的说明和备注,希望对您的项目有所帮助。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/707040.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复