


在Python中,我们经常需要处理缺失值,Pandas库提供了一些方法来处理这些缺失值,以下是一些常见的处理方法:

1、使用fillna()函数填充缺失值
2、使用dropna()函数删除含有缺失值的行或列
3、使用interpolate()函数进行插值填充
4、使用replace()函数替换特定值
以下是一些示例代码:
import pandas as pd
import numpy as np
创建一个包含缺失值的数据框
df = pd.DataFrame({'A': [1, 2, np.nan], 'B': [5, np.nan, np.nan], 'C': [1, 2, 3]})
print(df)
使用0填充所有的缺失值
df.fillna(value=0)
print(df)
使用前一个值填充缺失值
df.fillna(method='ffill')
print(df)
使用后一个值填充缺失值
df.fillna(method='bfill')
print(df)
使用平均值填充缺失值
df.fillna(value=df.mean())
print(df)
删除含有缺失值的行
df.dropna()
print(df)
删除含有缺失值的列
df.dropna(axis=1)
print(df)
使用线性插值填充缺失值
df.interpolate()
print(df)
使用特定值替换缺失值
df.replace(np.nan, 0)
print(df) 注意:在使用fillna()、dropna()、interpolate()和replace()函数时,如果不指定inplace=True,那么这些函数将返回一个新的数据框,原始数据框不会被改变,如果你想直接修改原始数据框,可以设置inplace=True。
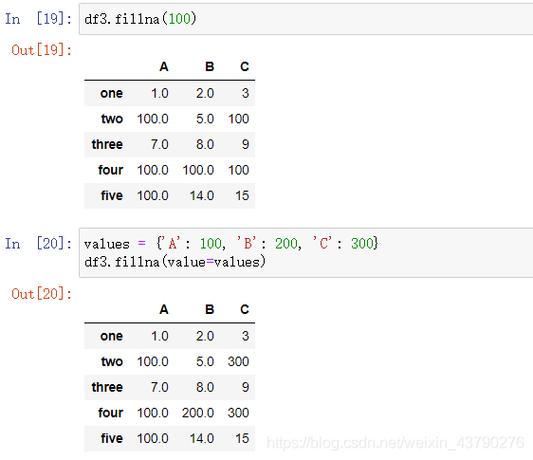
下面是一个简化的介绍,展示了在Python中处理缺失值时可能用到的一些空值填充(缺失值填充)方法:
| 方法 | 描述 | 示例代码 |
| 均值填充 | 用特征的平均值填充缺失值 | df['column'].fillna(df['column'].mean(), inplace=True) |
| 中位数填充 | 用特征的中位数填充缺失值 | df['column'].fillna(df['column'].median(), inplace=True) |
| 众数填充 | 用特征出现次数最多的值填充缺失值 | df['column'].fillna(df['column'].mode()[0], inplace=True) |
| 常量填充 | 用一个指定的常量填充缺失值 | df['column'].fillna('constant_value', inplace=True) |
| 插值法填充 | 通过插值方法(如线性或时间序列插值)填充缺失值 | df['column'].interpolate(method='linear', inplace=True) |
| 前向填充或后向填充 | 用前一个或后一个非缺失值填充缺失值 | df['column'].fillna(method='ffill', inplace=True)df['column'].fillna(method='bfill', inplace=True) |
| 使用模型预测 | 基于其他特征通过建模预测缺失值 | from sklearn.ensemble import RandomForestRegressormodel = RandomForestRegressor()df['column'][missing] = model.fit(X_train, y_train).predict(X_test) |
这个介绍只是一个简单的示例,实际应用中可能需要根据数据的特点和分析的需求选择合适的填充方法,示例代码假设你已经有一个名为df 的pandas DataFrame对象,并且要填充的列为'column'。
需要注意的是,在实际使用中,通常不建议直接使用inplace=True 参数,因为它会直接修改原始DataFrame,而更推荐创建新列或者新DataFrame以保留原始数据,例如使用df['column_filled'] = df['column'].fillna(df['column'].mean()),上述代码示例没有考虑缺失值的类型(例如数值缺失或分类数据缺失),在实际应用中也需要根据具体情况来选择合适的方法。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/706824.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复