


CarbonData 是一个基于 Apache Hadoop 和 Spark 的高性能数据存储解决方案,主要用于处理大规模数据分析,它通过列式存储、索引、压缩等技术优化查询性能,支持多种查询语言(如 SQL、Hive、SparkSQL 等),并可与现有的 Hadoop 生态系统无缝集成。
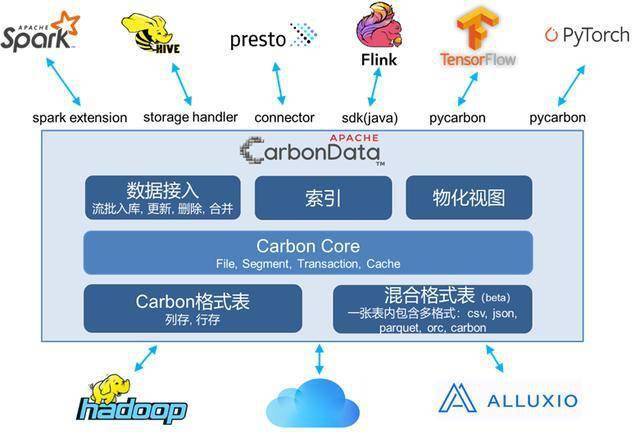

CarbonData 特点
列式存储:CarbonData 采用列式存储方式,可以有效减少 I/O 操作,提高查询速度。
索引:CarbonData 支持多种索引类型,如 B+ 树、倒排索引等,可以加速数据检索速度。
压缩:CarbonData 提供高效的数据压缩算法,可以降低存储成本。
数据编码:CarbonData 支持 Run Length Encoding (RLE)、Delta Encoding 等编码方式,进一步减小数据大小。
查询优化:CarbonData 支持谓词下推、过滤等查询优化技术,可以提高查询性能。
多语言支持:CarbonData 支持多种查询语言,如 SQL、Hive、SparkSQL 等。
兼容性:CarbonData 可以与现有的 Hadoop 生态系统无缝集成,兼容 Hive、Spark、Presto 等。
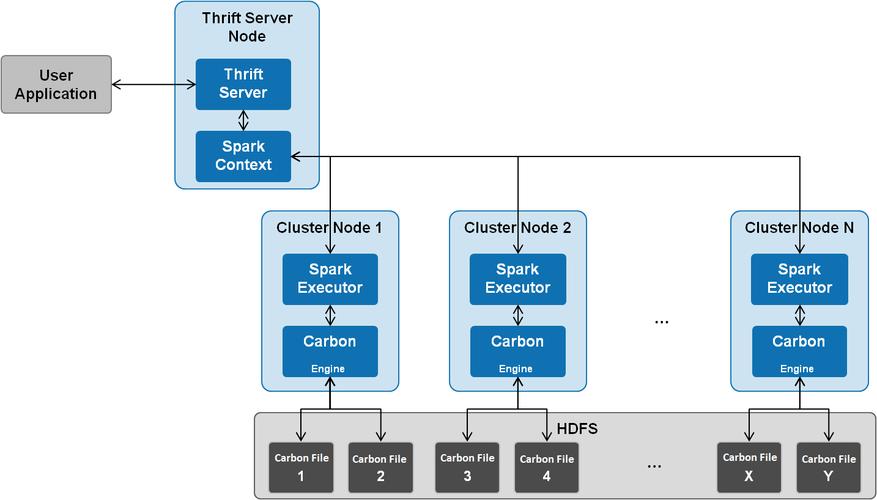
CarbonData 架构
CarbonData 主要由以下几个组件组成:
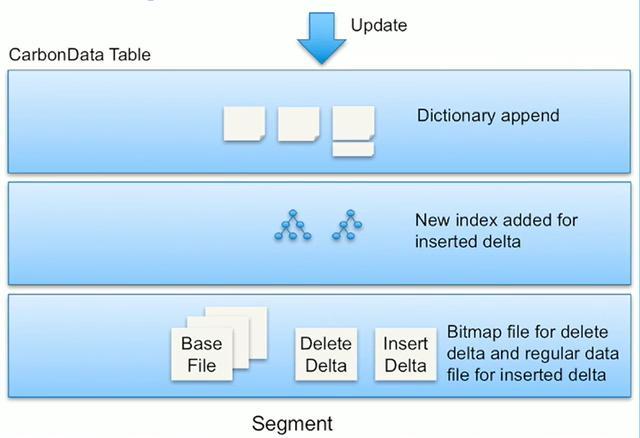
CarbonData Store:负责数据的存储和管理,包括数据的写入、读取、更新等操作。
CarbonData Index:负责索引的创建和管理,包括 B+ 树、倒排索引等。
CarbonData Query Engine:负责查询的执行和优化,包括谓词下推、过滤等。
CarbonData Compiler:负责将 SQL 查询转换为可执行计划。
CarbonData Driver:负责与外部系统的交互,如 Hive、Spark 等。
CarbonData 应用场景
CarbonData 主要适用于以下场景:
大数据仓库:CarbonData 可以作为大数据仓库的存储引擎,支持高并发的查询和分析。
实时分析:CarbonData 支持流式数据的实时写入和查询,适合实时数据分析场景。
历史数据查询:CarbonData 可以高效地处理历史数据的查询和分析。
机器学习:CarbonData 可以作为机器学习的数据存储和处理引擎。
CarbonData 是一个高性能的大数据存储和处理解决方案,适用于各种大规模数据分析场景。
以下是将以【carbondata群_CarbonData】为内容的介绍形式呈现:
| 群名称 | 群主题 |
| carbondata群 | CarbonData |
这个介绍包含了群名称和群主题两列,展示了一个关于CarbonData主题的群聊信息,如果需要更详细的信息,可以继续添加其他相关列。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/705226.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复