


电脑语音识别技术允许计算机通过麦克风捕捉声音,并将其转化为可理解的文本,这种技术在各种应用程序中都非常有用,包括语音命令、自动字幕生成、辅助技术等,以下是关于电脑端语音识别技术的详细分析,包括几个关键方面:


技术原理
1. 声音捕捉与处理
麦克风输入:使用高质量的麦克风可以显著提高语音识别的准确性,因为它能够更清晰地捕捉声音细节。
噪声抑制:软件通常会应用噪声抑制算法来减少背景噪音的干扰,如空调声、交通噪声等。
2. 语音到文本的转换
语音识别算法:现代语音识别系统通常采用深度学习模型,如循环神经网络或卷积神经网络来解析语音数据。
语言模型:为了提高识别准确性,系统会使用特定的语言模型来预测单词序列的概率。
应用场景
1. 办公自动化
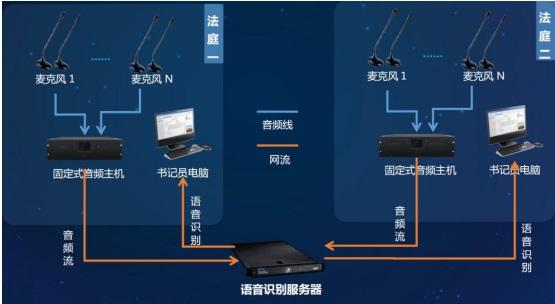
文档创建:语音识别可以帮助快速创建文档,提高工作效率,特别是对于打字不快的用户。
会议记录:自动记录会议内容并转成文字,方便会后复查和整理信息。
2. 辅助技术
视障支持:为视觉障碍人士提供语音输入,帮助他们更容易地使用计算机。
语音控制:使行动不便的用户可以通过语音命令操作电脑,无需使用物理设备。
性能考量
1. 准确率
清晰度与口音:发音的清晰度和是否含有浓重口音会影响识别的准确率。

专业术语处理:对于包含专业术语或不常用词汇的语音,系统可能需要进行特别训练以提高识别效果。
2. 实时性
延迟问题:在实时转写场景中,系统的处理速度需足够快,以保持对话的流畅。
资源占用:高效的算法可以减少对计算资源的占用,使得在不那么强大的硬件上也能运行。
用户界面与体验
1. 交互设计
易用性:用户界面应简洁直观,便于用户进行语音输入和其他交互操作。
可视化反馈:提供实时的声音波形图和文字预览,帮助用户调整语速和清晰度。
2. 定制化与适应性
个性化设置:允许用户根据自己的需求调整识别设置,如语速、音量等。
学习功能:系统应具备自我学习的功能,通过用户的持续使用逐渐提高对其特定声音和语调的识别准确性。
隐私与安全
1. 数据加密
传输加密:确保语音数据在传输过程中的安全,防止被拦截。
存储安全:本地存储的语音数据应加密,保护用户隐私不被未经授权访问。
2. 隐私政策
用户知情权:明确告知用户数据如何被收集、使用和存储的细节。
权限控制:用户应有权决定是否启用语音识别功能及管理自己的语音数据。
这些方面的综合考虑有助于全面评估电脑端语音识别技术的效能和适用性,从而更好地满足不同用户的需求和预期。
下面是一个简单的介绍,展示了电脑端语音识别的相关信息:
| 项目 | 描述 |
| 软件名称 | 电脑端语音识别软件名称 |
| 操作系统 | 支持的操作系统版本 |
| 兼容性 | 是否支持多种语言、方言识别 |
| 精确度 | 在不同环境下的识别精确度 |
| 实时性 | 语音识别的响应时间 |
| 麦克风要求 | 推荐使用的麦克风类型及最低要求 |
| 功能特点 | 如:语音转文字、语音命令、语音翻译等 |
| 使用场景 | 如:办公、学习、娱乐等 |
| 价格 | 软件的价格及收费方式 |
| 用户评价 | 用户对软件的整体满意度 |
这个介绍只是一个基本的框架,你可以根据实际需要添加或修改相关信息,希望对你有所帮助。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/705202.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复