




在现代的Web开发中,动态内容生成是常见的实践,但随之而来的是对服务器性能的挑战,为了优化搜索引擎蜘蛛的爬行效率和改善用户体验,网站HTML静态化成为了一种重要的优化手段,本文将指导您如何通过PHP实现网站的HTML静态化操作。
1. 理解HTML静态化的优势
HTML静态化指的是将原本需要服务器实时生成的动态页面转换为静态的HTML文件,这样做有几个显著的优点:
提高加载速度:静态页面直接由Web服务器提供,无需数据库查询和脚本执行,因此可以大幅减少页面加载时间。
降低服务器压力:减少了对后端服务器的请求,可以有效减轻服务器负担,尤其是在高流量情况下。
增强SEO:搜索引擎更易爬行静态页面,有助于提升搜索排名。
2. 准备环境
在开始之前,确保您的服务器满足以下条件:
安装有PHP环境(如Apache、Nginx等)。
具备写入权限的文件系统,用以存储生成的静态文件。
3. 设置URL路由规则
为了让蜘蛛能够爬行到静态页面,需要在网站的.htaccess文件中设置URL重写规则(如果使用Nginx,则需在配置文件中设置相应的规则):
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !f
RewriteCond %{REQUEST_FILENAME} !d
RewriteRule ^(.*)$ index.php?path=$1 [L,QSA] 这条规则意味着,如果请求的文件或目录不存在,请求会被重定向到index.php,并把原始请求路径作为参数传递。
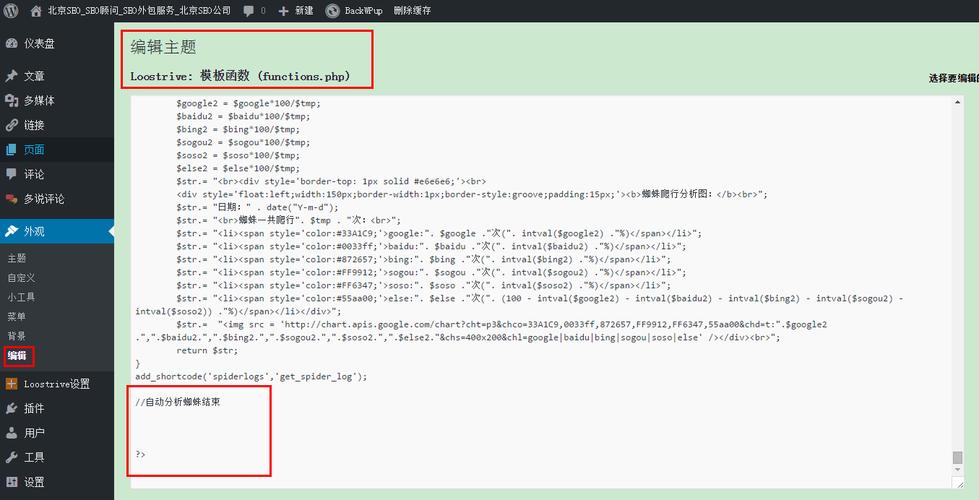
4. 编写爬虫逻辑
我们需要在index.php中添加逻辑来处理这些请求,当接收到一个请求时,首先检查是否存在对应的静态HTML文件,如果存在,则直接返回该文件;如果不存在,则生成新的静态文件。
$path = $_GET['path'] ?? '';
$staticFilePath = "/path/to/static/files/" . $path . ".html";
if (file_exists($staticFilePath)) {
readfile($staticFilePath);
exit;
} else {
// 这里进行动态内容的生成,例如从数据库中获取数据
$content = getDynamicContent($path);
// 将内容写入静态文件
file_put_contents($staticFilePath, $content);
// 输出内容到浏览器
echo $content;
} 5. 定时任务与更新机制
为了保持静态页面内容的时效性,可以通过设置定时任务(如cron job)定期清除旧的静态文件,并重新生成,也可以在内容更新时触发静态文件的重新生成。
6. 测试与部署
在实施上述步骤后,进行全面测试以确保一切正常运行,这包括检查静态页面是否正确生成,URL重写规则是否生效,以及定时任务是否按计划执行,确认无误后,可以将改动部署到生产环境。
7. 监控与维护
部署完成后,持续监控网站的性能和蜘蛛爬行行为,关注以下几个方面:
页面加载速度是否有所提升。
服务器负载是否降低。
搜索引擎的索引频率和排名变化。
根据监控结果调整策略,以保持最佳的性能和SEO效果。
相关问答FAQs
Q1: 如果网站内容频繁更新,HTML静态化是否还适用?
A1: 对于内容更新非常频繁的网站,HTML静态化可能不是最佳选择,因为每次内容更新都需要重新生成静态文件,这样会增加系统的复杂性和开销,在这种情况下,可以考虑结合使用缓存技术,如Redis或Memcached,来减少数据库查询次数,同时保持内容的实时性。
Q2: HTML静态化是否会增加管理难度?
A2: 是的,HTML静态化确实会增加一些管理上的复杂性,特别是在处理文件的生成、更新和删除时,需要确保有一套完善的机制来管理这些静态文件,避免产生过时的内容或占用过多的磁盘空间,也需要考虑到安全性问题,确保静态文件不会被恶意利用。
下面是一个简化的介绍,描述了PHP蜘蛛爬行记录和启用网站HTML静态化操作的步骤:
| 步骤 | PHP蜘蛛爬行记录 | 启用网站HTML静态化 |
| 1 | 确定目标网站 | 选择静态化内容 |
| 2 | 设计爬虫规则 | 确定静态化技术 |
| 3 | 编写爬虫脚本 | 配置服务器环境 |
| 4 | 测试爬虫脚本 | 开发静态化逻辑 |
| 5 | 开始爬行 | 部署静态化脚本 |
| 6 | 记录爬行数据 | 测试静态化效果 |
| 7 | 分析爬行结果 | 监控性能与SEO表现 |
| 8 | 调整爬行策略 | 优化静态化流程 |
| 9 | 维护爬虫脚本 | 更新静态化内容 |
| 10 | 遵守法律与规范 | 保证内容更新及时性 |
以下是对每一步的具体说明:
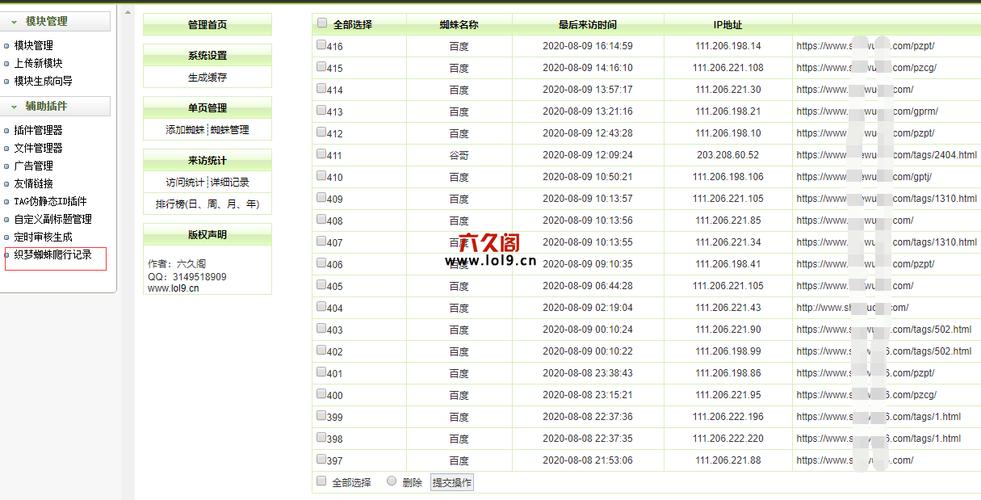
PHP蜘蛛爬行记录:
1、确定目标网站:选择需要爬取内容的网站。
2、设计爬虫规则:包括爬取的深度、频率、需要抓取的数据等。
3、编写爬虫脚本:使用PHP编写爬虫脚本,如使用cURL库或file_get_contents()函数获取网页内容。
4、测试爬虫脚本:在本地环境或测试环境中运行爬虫脚本,确保其按预期工作。
5、开始爬行:在确保无误后,让爬虫脚本开始抓取网站数据。
6、记录爬行数据:将爬取的数据记录到数据库或文件中。
7、分析爬行结果:分析抓取的数据,提取有用信息。
8、调整爬行策略:根据分析结果调整爬虫的抓取策略。
9、维护爬虫脚本:定期更新脚本以应对网站结构变化,并确保爬虫遵守相关法律法规。
10、遵守法律与规范:确保爬虫行为符合法律法规和网站robots.txt文件的规定。
启用网站HTML静态化:
1、选择静态化内容:确定哪些页面或内容需要被静态化。
2、确定静态化技术:选择合适的静态化技术,如使用PHP的file_put_contents()函数生成静态HTML。
3、配置服务器环境:确保服务器环境支持静态化操作。
4、开发静态化逻辑:编写PHP代码,将动态内容转换为静态HTML。
5、部署静态化脚本:将静态化脚本部署到服务器上。
6、测试静态化效果:确保生成的静态页面能够正确显示,并且链接等元素正常工作。
7、监控性能与SEO表现:评估静态化对网站性能和搜索引擎优化(SEO)的影响。
8、优化静态化流程:根据性能和SEO监控结果,优化静态化流程。
9、更新静态化内容:定期更新静态页面,保证内容的时效性。
10、更新及时性:确保在内容发生变化时,静态页面也能得到及时更新。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/704460.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复