


爬虫队列_配置网站反爬虫防护规则防御爬虫攻击
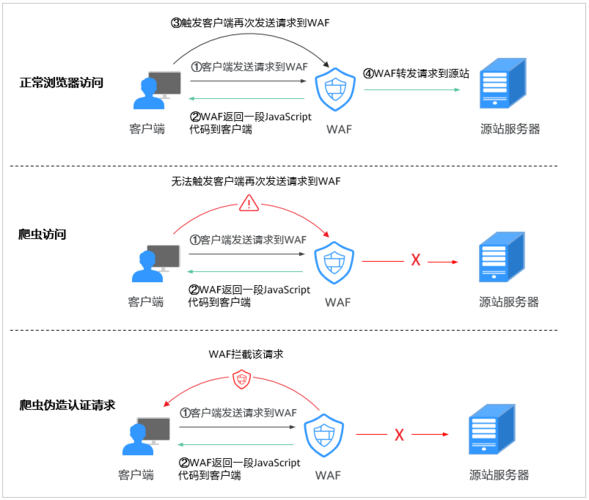

在数字化时代,数据是企业的重要资产,网络爬虫(Web Crawler)的滥用给许多网站带来了安全和隐私问题,爬虫队列的配置和网站的反爬虫防护措施对于保护网站资源、防止敏感信息泄露至关重要,本文将介绍如何通过配置反爬虫防护规则来防御爬虫攻击。
基础防护策略
设置Robots.txt文件
每个网站都应有一个Robots.txt文件,该文件位于网站的根目录,它用来告诉遵循规范的爬虫哪些页面可以抓取,哪些不可以。
Useragent: * Disallow: /private/ Disallow: /admin/
上述代码表示所有爬虫不得访问private和admin目录下的内容。
使用HTTP头限制访问
通过设置HTTP响应头,如XRobotsTag或XFrameOptions,可以进一步控制爬虫行为,禁止页面被嵌入到frame中:
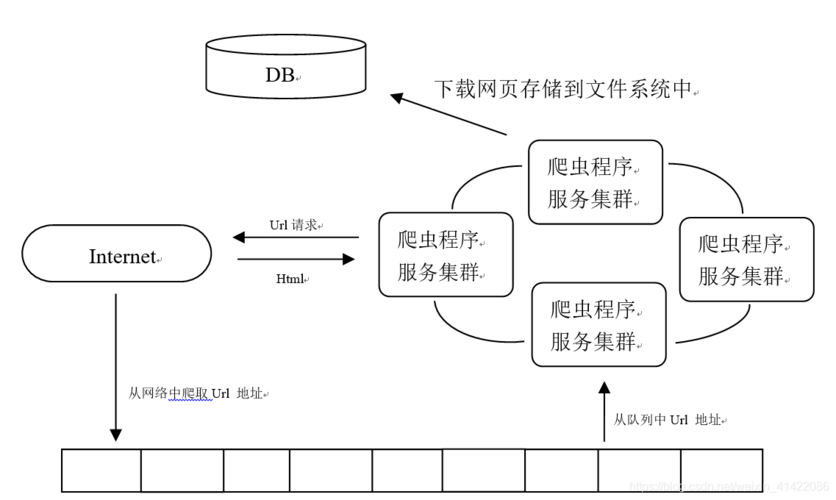
XFrameOptions: DENY
实施用户代理检测
识别并屏蔽具有爬虫特征的用户代理字符串是一种简单有效的方法,虽然一些高级爬虫可以伪装用户代理,但此方法仍可阻挡大部分低级爬虫。
限制访问频率
通过限制单个IP地址在一定时间内的请求次数,可以有效减缓爬虫对服务器的冲击,这通常通过中间件实现,并需要根据实际流量调整阈值。
启用验证码机制
对于表单提交等敏感操作,引入验证码机制可以有效阻止自动化爬虫脚本的运行。
进阶防护手段
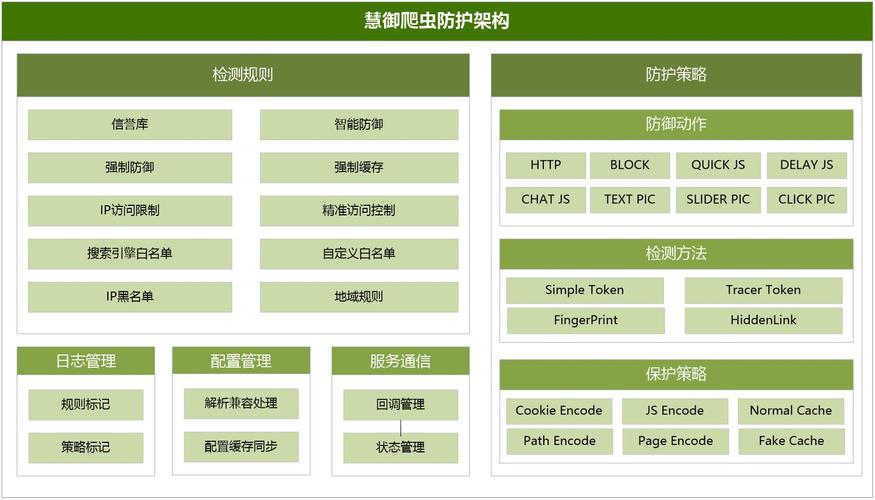
动态网页技术
利用JavaScript生成页面内容,使得传统爬虫难以解析,关键内容可以通过AJAX请求加载,增加爬虫的工作难度。
行为分析与模式识别
监控访问者的行为模式,如鼠标移动、滚动速度、点击间隔等,可以区分人类用户与爬虫程序,异常行为触发额外的验证步骤或直接封锁访问。
使用蜜罐技术
创建特定的“陷阱”页面,只有爬虫才会访问到这些页面,一旦检测到对这些页面的访问,即可识别出爬虫并进行封禁。
实施API限制
如果网站提供API服务,应限制API密钥的使用频率和范围,避免被滥用于大规模数据抓取。
法律和技术相结合
在网站上明确声明版权和使用条款,对于违规爬虫采取法律手段进行威慑,结合技术手段,确保法律声明的执行力。
相关问答FAQs
Q1: 配置反爬虫防护规则是否会影响正常用户的体验?
A1: 正确配置的反爬虫措施通常不会影响正常用户的体验,通过行为分析来识别非人类访问模式,只有在检测到自动化访问时才会触发额外的防护措施,过于严格的限制可能会误伤合法用户,因此需要细致调整以平衡安全性和用户体验。
Q2: 反爬虫防护规则能否完全阻止爬虫攻击?
A2: 没有任何系统能够保证百分之百的安全性,反爬虫防护规则也不例外,尽管可以大幅提高攻击者的成本和难度,但高级的攻击者可能会采用更复杂的手段,如模拟人类行为、使用分布式爬虫系统等,持续监控、定期更新防护策略以及结合其他安全措施是非常重要的。
配置有效的反爬虫防护规则是维护网站安全、保护数据不被非法抓取的重要环节,通过基础防护策略与进阶防护手段的结合,可以构建起强有力的防线,需要注意的是,随着技术的发展,防护措施也需要不断更新迭代,以应对日益狡猾的爬虫攻击。
以下是一个关于配置网站反爬虫防护规则的介绍,用于防御爬虫攻击:
| 序号 | 防护规则名称 | 规则描述 | 配置方法 | 作用 |
| 1 | API访问限制 | 限制API请求频率,防止自动化爬虫大量请求 | 1. 设置访问频率限制,如每分钟请求次数上限; 2. 设置访问令牌或API密钥,验证请求者身份。 | 防止自动化爬虫对API进行大量请求,保障API服务稳定。 |
| 2 | 数据加密 | 对用户敏感数据进行加密,降低数据被抓取的风险 | 使用加密算法(如AES、RSA等)对用户敏感数据进行加密。 | 确保即使数据被抓取,也无法被窃取有意义的信息。 |
| 3 | 用户行为分析 | 分析用户行为和请求模式,识别自动化爬虫行为 | 1. 检测大量连续的请求; 2. 检测相同的请求频率; 3. 设置正常用户行为模型,与异常行为进行对比。 | 识别并阻止自动化爬虫行为,减少数据被抓取的风险。 |
| 4 | 动态防护 | 对HTML和JavaScript源码进行动态加密,防止爬虫解析和模拟攻击 | 使用动态防护工具(如雷池WAF的safelinechaos容器)对源码进行加密。 | 使自动化工具难以分析和模拟正常用户行为,提升网站安全。 |
| 5 | 华为云WAF反爬虫 | 利用华为云WAF进行多维度检测和防护,防止恶意爬虫扫描和攻击 | 1. 开启Robot检测; 2. 开启网站反爬虫; 3. 配置CC攻击防护。 | 有效阻断恶意爬虫、SQL注入、跨站脚本攻击等威胁,保障Web服务安全稳定。 |
| 6 | 速盾高防CDN | 通过部署先进的防御技术,保护网站免受包括恶意爬虫在内的多种网络攻击 | 1. 利用分布式架构和全球节点处理大规模攻击流量; 2. 应用智能技术如机器学习和行为分析进行侦测和阻挠; 3. 配置Web应用程序防火墙(WAF)。 | 提供强大的防护性能,防止敏感信息被盗取,保障用户访问安全和数据保护。 |
| 7 | SVG映射/数字映射 | 对爬虫进行视觉识别干扰,提高爬虫抓取难度 | 在网页中添加SVG映射或数字映射,使爬虫难以识别和解析内容。 | 增加爬虫抓取成本,降低被抓取的风险。 |
| 8 | IP限制 | 限制特定IP地址的访问,防止恶意爬虫大量请求 | 1. 设置IP白名单,只允许特定IP地址访问; 2. 设置IP黑名单,禁止特定IP地址访问。 | 防止恶意爬虫从特定IP地址发起的大量请求,保障网站服务稳定。 |
这个介绍列举了一些常见的网站反爬虫防护规则,可以根据实际需求进行选择和配置,需要注意的是,这些规则并非绝对有效,防护效果可能会因爬虫的攻击方式和策略而有所不同,建议综合运用多种防护规则,以提高网站的安全性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/704304.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复