


大数据与数据仓库

1.
1.1 大数据
大数据是指无法在合理时间内用常规数据库管理工具进行捕捉、管理和处理的大规模、高增长率和多样化的信息资产集合。
1.1.1 特点
体量大:数据量巨大,通常以TB、PB或EB为单位。
速度快:数据生成速度极快,需要实时或准实时处理。
种类多:包括结构化数据、半结构化数据和非结构化数据。
1.2 数据仓库
数据仓库是一个面向主题、集成、相对稳定、反映历史变化的数据集合,用于支持管理决策。
1.2.1 特点
面向主题:按照业务主题组织数据,如销售、库存等。
集成:将来自不同源的数据整合在一起。
相对稳定:数据一旦加载到数据仓库中,就很少发生变化。
反映历史变化:存储历史数据,便于分析趋势和模式。
2. 大数据技术架构
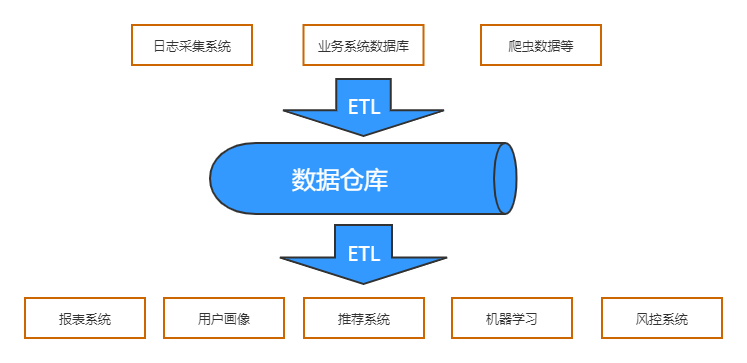
2.1 数据采集
日志采集:Flume、Logstash等。
网络爬虫:抓取网页数据。
2.2 数据存储
分布式文件系统:HDFS、GlusterFS等。
NoSQL数据库:MongoDB、Cassandra等。
列式存储:HBase、Cassandra等。
2.3 数据处理
批处理:Hadoop MapReduce、Spark等。
流处理:Storm、Flink等。
2.4 数据分析
数据挖掘:关联规则挖掘、聚类分析等。
机器学习:分类、回归、聚类等算法。
3. 数据仓库设计
3.1 数据模型
星型模型:一个事实表和多个维度表。
雪花模型:星型模型的变种,维度表进一步规范化。
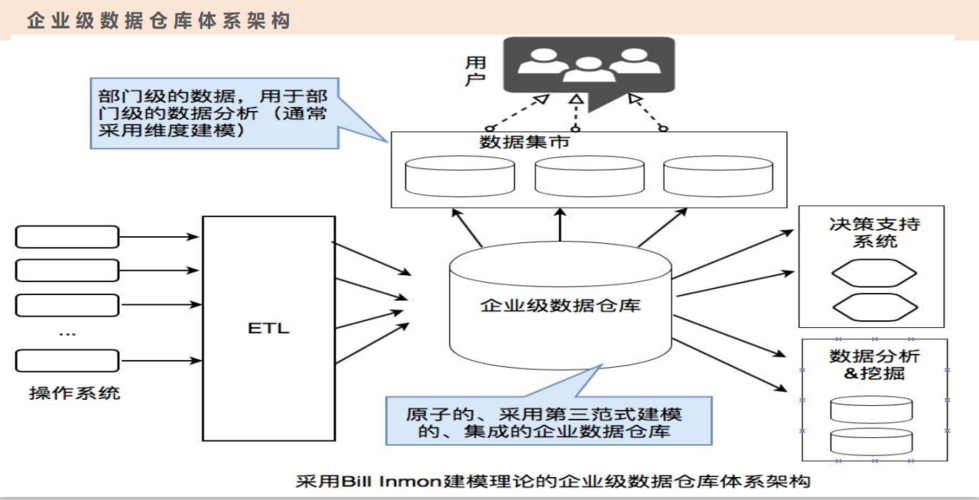
3.2 ETL过程
抽取:从源系统抽取数据。
转换:清洗、转换数据。
加载:将数据加载到数据仓库。
3.3 数据立方体
OLAP:在线分析处理,支持多维数据分析。
数据切片:按维度切分数据,提高查询性能。
4. 大数据与数据仓库的关系
4.1 互补性
大数据:侧重于实时或近实时处理大量、多样的数据。
数据仓库:侧重于存储历史数据,支持复杂的决策分析。
4.2 整合方式
数据湖:存储原始数据的集中式存储库,可作为大数据与数据仓库之间的桥梁。
Lambda架构:将大数据处理分为批量处理和实时处理两层,最终结果统一存储在数据仓库中。
5. 应用场景
5.1 大数据应用
互联网搜索:实时处理海量搜索请求和点击数据。
金融风控:实时分析交易数据,识别欺诈行为。
5.2 数据仓库应用
销售分析:分析历史销售数据,制定销售策略。
库存管理:监控库存水平,优化库存成本。
下面是一个关于大数据与数据仓库(特指数据仓库)的对比介绍:
| 特性/概念 | 大数据平台 | 数据仓库 |
| 定义 | 大数据是指无法使用常规软件工具在合理时间内捕捉、管理和处理的大量数据,它涉及非结构化或半结构化数据的处理和分析。 | 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,主要用于支持管理决策。 |
| 数据类型 | 结构化、半结构化、非结构化数据 | 结构化数据 |
| 数据源 | 企业内部和外部的多种数据源,例如社交媒体、日志文件、传感器数据等。 | 主要来自企业内部应用系统,如ERP、CRM等。 |
| 存储技术 | 通常使用Hadoop、Spark等分布式存储和处理技术。 | 传统数据库或专为数据仓库设计的数据库,如Oracle、Teradata等。 |
| 数据处理 | 强调实时处理和批量处理,使用MapReduce、Spark等计算模型。 | 主要进行批量处理,ETL(提取、转换、加载)是核心过程。 |
| 数据模式 | 无需预先定义模式,数据湖等技术允许在存储后定义模式。 | 需要预先定义模式,为分析提供单一的真理来源。 |
| 分析能力 | 支持复杂的数据分析和数据挖掘,如机器学习、深度学习等。 | 主要支持OLAP(联机分析处理),提供数据挖掘、报表和分析查询。 |
| 扩展能力 | 水平扩展能力强,可以通过增加节点处理更多数据。 | 纵向扩展能力有限,通常通过增加硬件资源提升处理能力。 |
| 数据治理 | 灵活的数据治理策略,但需要特别关注数据质量和安全。 | 严格的数据治理,强调数据质量、一致性和安全。 |
| 使用场景 | 适用于大量数据的存储、处理和分析,如互联网公司、物联网等。 | 适用于企业级的数据分析和决策支持,如财务报告、销售分析等。 |
这个介绍简要概述了大数据平台与数据仓库之间的关键区别,在实际应用中,许多企业会结合使用这两种技术,以充分利用各自的优势。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/704156.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复