


大数据分析数据库
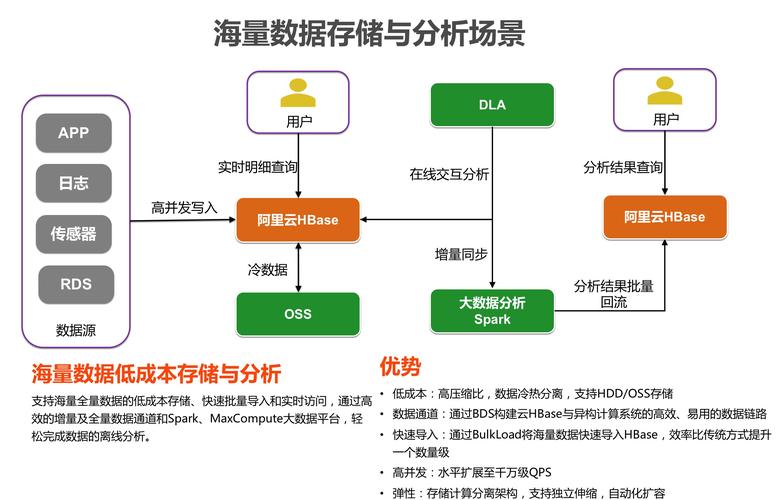

大数据分析是指通过使用先进的分析技术和工具从大量数据中提取信息、发现模式和预测未来趋势的过程,为了有效地处理和分析这些庞大的数据集,需要使用专门的数据库系统,以下是一些在大数据分析中常用的数据库类型:
1. 关系型数据库(RDBMS)
关系型数据库管理系统如Oracle, MySQL, PostgreSQL等,它们基于表格形式存储数据,并支持SQL查询,适用于结构化数据的存储和检索。
2. NoSQL数据库
NoSQL数据库如MongoDB, Cassandra, DynamoDB等,设计用于分布式数据存储,能够处理大量的非结构化或半结构化数据,它们通常提供更高的可扩展性和灵活性。
3. 列式数据库
列式数据库如Google BigTable, Apache HBase等,优化了读操作,特别适用于需要快速聚合大量数据的分析任务。
4. 时间序列数据库
时间序列数据库如InfluxDB, OpenTSDB等,专门用于存储时间序列数据,例如股票价格、服务器日志等,它们提供了高效的时间范围查询功能。
5. 数据仓库
数据仓库如Amazon Redshift, Google BigQuery, Snowflake等,设计用于存储和管理企业级的数据,支持复杂的查询和报告功能。
6. 实时数据处理系统
实时数据处理系统如Apache Kafka, Apache Flink等,能够处理流数据并提供实时分析。
大数据分析

大数据分析涉及以下几个关键步骤:
数据收集
数据收集是大数据分析的第一步,涉及从各种来源(如社交媒体、传感器、日志文件等)获取数据。
数据预处理
数据预处理包括清洗、转换和整合数据,以便进行分析,这可能包括去除重复记录、处理缺失值、标准化数据格式等。
数据存储
数据存储涉及将处理后的数据保存在适当的数据库中,以便于分析和检索。
数据分析
数据分析是核心步骤,使用统计、机器学习和数据挖掘技术来发现数据中的模式和关联。
数据可视化
数据可视化帮助用户理解分析结果,通过图表、图形和仪表板等形式展示数据。
数据解释
数据解释是将分析结果转化为业务洞察和决策支持的过程。
相关问答FAQs
Q1: 大数据分析中使用的数据库与传统数据库有何不同?
A1: 大数据分析中使用的数据库通常设计为处理更大规模的数据集,提供更高的性能和可扩展性,它们可能采用不同的数据模型(如键值对、文档、列式存储),并且优化了读写操作,以适应复杂的查询和实时分析需求。
Q2: 如何选择合适的大数据分析数据库?
A2: 选择合适的大数据分析数据库需要考虑数据的类型、规模、访问模式以及预算和技术栈,对于结构化数据,关系型数据库可能是一个好选择;对于大规模非结构化数据,NoSQL数据库可能更合适;如果需要实时分析,那么实时数据处理系统将是必需的,还应该考虑数据库的易用性、社区支持和成本效益。
以下是一个关于大数据分析数据库的介绍示例,该介绍展示了在分析大数据时可能会用到的关键指标和概念:
| 分析指标/概念 | 描述 | 应用场景 |
| 平均值(Mean) | 数据集中所有数值的平均值 | 衡量数据集中趋势 |
| 中位数(Median) | 将数据集按大小排序后位于中间的数值 | 稳定描述数据集中趋势,不受极端值影响 |
| 众数(Mode) | 数据集中出现次数最多的值 | 描述分类数据的集中趋势 |
| 标准偏差(Standard Deviation) | 描述数据分布的离散程度 | 衡量数据波动大小 |
| 方差(Variance) | 数据点与平均值之间差异的平方的平均数 | 衡量数据离散程度 |
| 峰度(Kurtosis) | 描述数据分布形态的尖峭程度 | 识别数据分布的尾部厚度 |
| 偏度(Skewness) | 描述数据分布的对称性 | 识别数据分布的倾斜方向 |
| 极差(Range) | 数据集中最大值与最小值之差 | 描述数据分布的全距 |
| 四分位数(Quartiles) | 将数据集分为四等份的数值 | 描述数据的分布情况,尤其是中间50%的数据分布 |
| 最大值/最小值(Max/Min) | 数据集中的最大值和最小值 | 确定数据范围 |
| 总和(Sum) | 数据集中所有数值的总和 | 计算总量指标 |
| 总个数(Count) | 数据集中的数据点数量 | 确定数据集大小 |
| 置信度(Confidence Level) | 统计推断的可靠程度 | 确定估计结果的置信区间 |
| 相关性分析(Correlation Analysis) | 两个变量之间关系的强度和方向 | 分析变量间的关联程度 |
| 回归分析(Regression Analysis) | 用于预测一个变量基于一个或多个其他变量的值 | 建立变量间的预测模型 |
| 主成分分析(PCA) | 通过降维保留数据集中的主要特征 | 数据降维,减少计算复杂度 |
这个介绍仅供参考,实际大数据分析中可能会涉及更多指标和概念,根据具体的业务场景和分析需求,可以适当调整和扩展这个介绍。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/702508.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复