


diff函数在机器学习中通常指的是差分操作,用于处理时间序列数据,在机器学习端到端场景中,diff函数可以用于特征工程、预处理和模型训练等环节,下面是一个详细的解析:
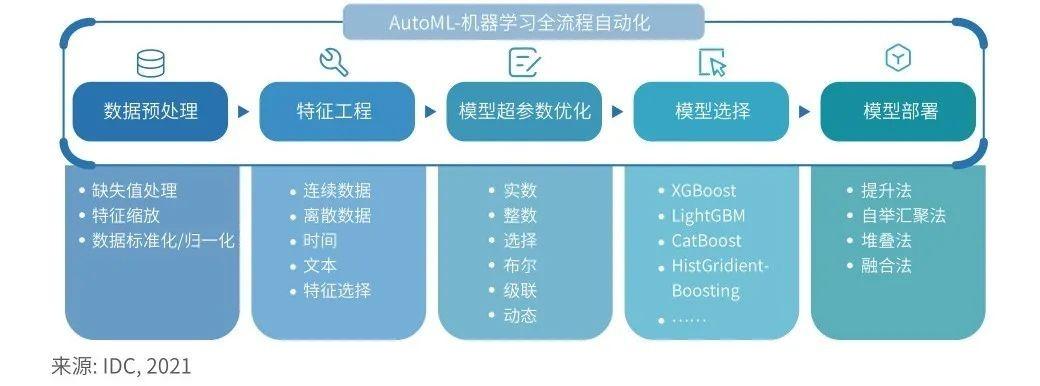

1、特征工程
在特征工程阶段,可以使用diff函数对时间序列数据进行差分操作,以提取数据的趋势和周期性信息,差分操作可以帮助消除数据的非平稳性,使得数据更适合用于机器学习模型的训练。
对于时间序列数据data,可以使用以下代码进行一阶差分:
import pandas as pd data = pd.Series([1, 2, 3, 4, 5]) diff_data = data.diff()
2、预处理
在预处理阶段,可以使用diff函数对数据进行标准化、归一化等操作,以便更好地适应机器学习模型,差分操作可以帮助消除数据的量纲影响,使得不同特征之间的数值更加可比。
对于包含多个特征的数据features,可以使用以下代码进行差分操作:
features = pd.DataFrame({'feature1': [1, 2, 3, 4, 5],
'feature2': [10, 20, 30, 40, 50]})
diff_features = features.diff() 3、模型训练
在模型训练阶段,可以使用差分操作对输入数据进行处理,以便更好地适应机器学习模型,差分操作可以帮助提取数据的变化趋势,从而提高模型的预测性能。
对于使用线性回归模型进行预测的场景,可以使用以下代码对输入数据进行差分操作:
import numpy as np from sklearn.linear_model import LinearRegression X = np.array([[1, 2, 3], [2, 3, 4], [3, 4, 5]]) y = np.array([1, 2, 3]) X_diff = np.diff(X, axis=0) y_diff = np.diff(y) model = LinearRegression() model.fit(X_diff, y_diff)
diff函数在机器学习端到端场景中主要用于处理时间序列数据,包括特征工程、预处理和模型训练等环节,通过差分操作,可以提取数据的趋势和周期性信息,消除数据的非平稳性,提高模型的预测性能。
下面是一个介绍,展示了diff函数在机器学习中的用途,以及端到端学习在机器学习场景中的应用。
| 特性/场景 | 描述 |
diff函数 | |
| 用途 | 用于计算序列数据(如时间序列)中连续元素之间的差异,这在机器学习中经常用于时间序列分析,可以帮助识别数据的趋势和周期性。 |
| 应用示例 | 1. 在时间序列预测中,计算连续时间点观测值的变化量。 2. 在股票价格分析中,通过 diff函数识别价格趋势。3. 在语音识别中,分析音频信号的连续变化以提取特征。 |
| 优点 | 简单易用,有助于捕捉数据的局部变化和趋势。 |
| 缺点 | 可能无法捕捉到更复杂的变化模式,仅限于序列数据的简单差分。 |
| 端到端学习 | |
| 定义 | 端到端学习是指将整个学习过程作为一个整体来训练模型,从原始输入数据直接学习到最终输出,不需要手动特征提取或复杂的预处理步骤。 |
| 场景应用 | 1. 在自动驾驶中,端到端模型可以直接从传感器数据预测车辆控制命令。 2. 在自然语言处理中,端到端模型如序列到序列(seq2seq)模型可以直接将一种语言翻译成另一种语言。 3. 在图像识别中,卷积神经网络(CNN)可以作为端到端模型,直接从原始像素数据中分类图像内容。 |
| 优点 | 减少了人工特征工程的负担,允许模型自动学习数据的复杂表示,提高了学习效率。 |
| 缺点 | 需要大量的训练数据和计算资源,且模型内部的黑箱特性可能导致解释性差。 |
这个介绍总结了diff函数在处理序列数据时的作用,以及端到端学习在机器学习领域中的应用场景、优缺点,希望这能帮助您更好地理解这些概念在机器学习中的角色。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/701608.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复