


大数据文件管理技术
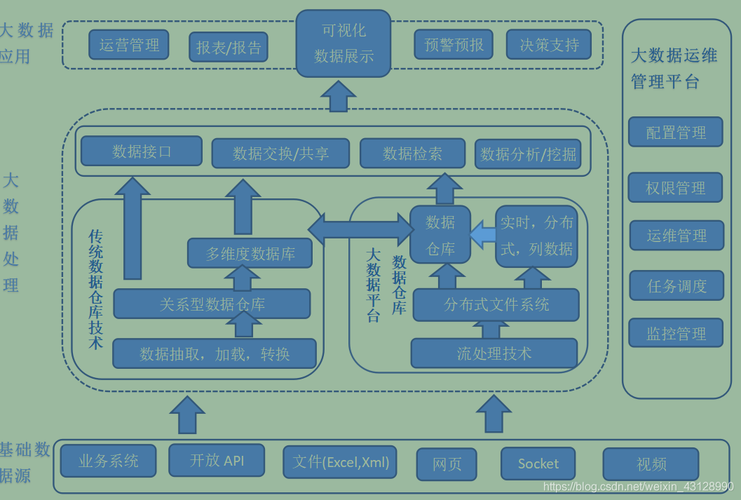

在当前信息化快速发展的时代,数据量呈指数级增长,大数据文件管理成为企业和组织面临的重要挑战,有效的文件管理技术不仅可以提高数据处理效率,还能确保数据的安全性和完整性,本文将探讨大数据文件管理中的关键技术栈及其应用。
分布式文件系统
分布式文件系统是大数据文件管理的基石,它允许数据跨多个物理服务器存储,提高了数据的可靠性和访问速度,典型的分布式文件系统包括Hadoop Distributed File System (HDFS)、Google File System (GFS)等。
HDFS:专为高吞吐量的数据访问和存储海量数据设计,通过数据块的冗余复制机制保证数据的高可用性。
GFS:Google的文件系统,同样采用分布式存储,支持大文件的高效存取。
数据湖
数据湖是一个存储大量原始数据的平台,支持结构化和非结构化数据,它允许用户直接存储数据,而无需事先定义数据模式,Apache Hadoop和Apache Spark常被用来处理存储在数据湖中的数据。
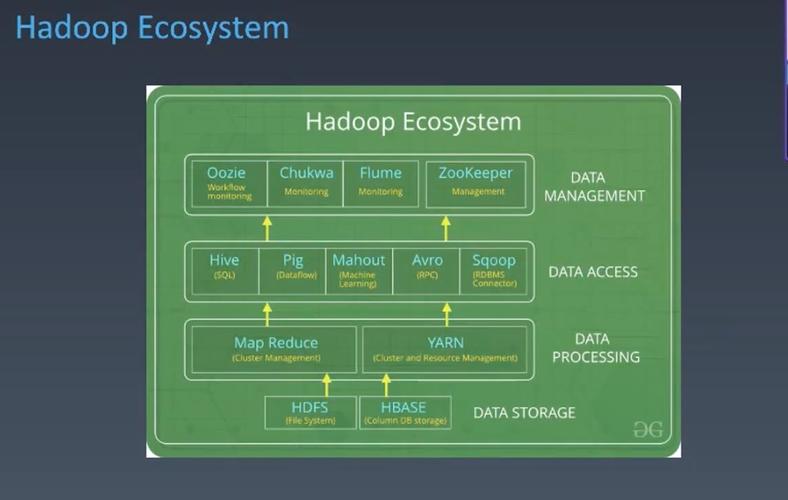
数据仓库
与数据湖不同,数据仓库存储的是经过处理和优化的结构化数据,适用于复杂的查询操作和分析,常见的数据仓库技术有Amazon Redshift、Google BigQuery和Snowflake。
实时数据处理
对于需要即时响应的应用,如金融交易和在线游戏,实时数据处理技术至关重要,Apache Kafka和Apache Flink是这一领域的佼佼者。
Apache Kafka:一个分布式流处理平台,用于构建实时数据管道和应用。
Apache Flink:提供高性能、精确一次状态化的分布式数据处理。
数据索引与搜索
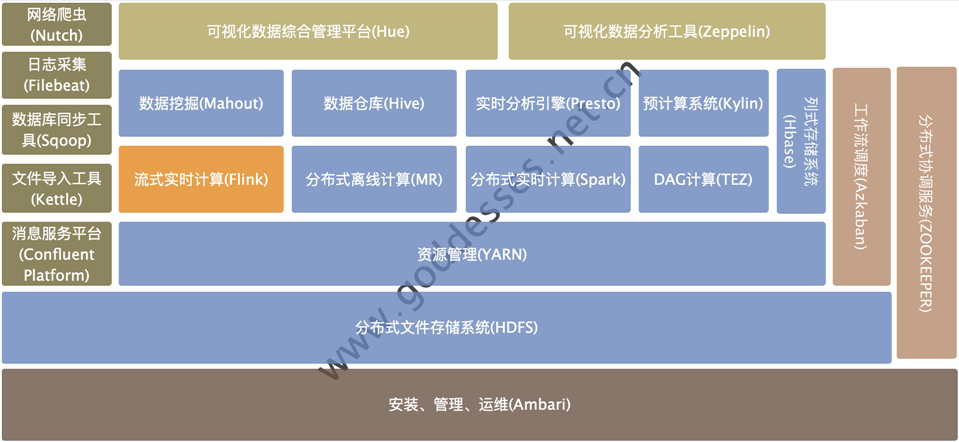
为了快速检索大量数据,高效的数据索引和搜索技术是必不可少的,Elasticsearch和Apache Solr是两种广泛使用的搜索和索引解决方案。
Elasticsearch:基于Lucene的搜索引擎,提供分布式、多租户能力的全文搜索引擎。
Apache Solr:也是基于Lucene,专为处理网络规模的文本。
数据压缩与编码
在大数据环境中,数据压缩可以显著减少存储空间需求和网络传输成本,常用的压缩算法包括GZIP、Snappy和LZO。
数据加密与安全
保护数据不被未授权访问是大数据文件管理的另一重要方面,技术如SSL/TLS加密、Kerberos认证和AES加密标准被广泛应用于数据传输和存储过程中。
数据备份与恢复
定期备份和有效的数据恢复策略对于防止数据丢失至关重要,分布式系统中常用的备份方法包括RAID技术和定期的数据快照。
数据治理与元数据管理
良好的数据治理保证了数据的质量和一致性,元数据管理工具如Apache Atlas和Collibra帮助组织理解和管理其数据资产。
相关技术栈管理
在大数据文件管理中,技术栈的选择和管理是实现高效数据操作的关键,以下是一些管理策略:
技术选型:根据业务需求和现有IT基础设施选择合适的技术组合。
性能监控:持续监控系统性能,确保数据处理和存取效率。
成本控制:评估各种技术的成本效益,包括存储、处理和人力成本。
安全性审核:定期进行安全审计,确保数据安全措施的有效性。
培训与支持:为技术人员提供必要的培训,并建立技术支持体系。
FAQs
Q1: 大数据文件管理系统中如何平衡存储成本和性能?
A1: 可以通过选择成本效益高的存储解决方案、实施数据压缩技术以及优化数据存储格式来降低存储成本,通过使用高效的数据处理框架和算法来提升性能,确保系统的高效运行。
Q2: 在实施大数据文件管理系统时,如何确保数据的一致性和完整性?
A2: 应实施严格的版本控制和变更管理流程,采用数据校验和错误校正技术来检测和纠正数据错误,定期进行数据质量评估和审计,以确保数据的一致性和完整性。
| 序号 | 技术领域 | 技术名称 | 技术描述 | 技术栈管理 |
| 1 | 数据存储 | Hadoop HDFS | 分布式文件存储系统,用于存储大数据,具有高可靠性、高吞吐量和可扩展性。 | Hadoop生态系统的一部分 |
| 2 | 数据计算 | MapReduce | 分布式数据处理框架,用于大数据计算。 | Hadoop生态系统的一部分 |
| 3 | 数据查询 | Hive | 基于Hadoop的数据仓库工具,用于数据查询、分析和处理。 | Hadoop生态系统的一部分 |
| 4 | 流式处理 | Apache Kafka | 高吞吐量的分布式消息队列系统,用于实时数据处理。 | 独立技术栈,可与多种系统整合 |
| 5 | 实时计算 | Apache Flink | 分布式实时数据处理框架,支持流处理和批处理。 | 独立技术栈,与Apache Kafka等整合 |
| 6 | 内存计算 | Apache Spark | 分布式内存计算框架,用于快速处理大数据。 | 独立技术栈,可与Hadoop等整合 |
| 7 | 数据仓库 | Amazon Redshift | 云数据仓库服务,用于存储和分析大规模数据集。 | AWS云服务 |
| 8 | 数据挖掘 | Apache Mahout | 基于Hadoop的机器学习库,用于数据挖掘。 | Hadoop生态系统的一部分 |
| 9 | 文件存储 | Alluxio | 内存级速度的虚拟分布式存储系统,用于加速数据访问。 | 独立技术栈,与Hadoop等整合 |
| 10 | 数据同步 | Apache Sqoop | 用于在Hadoop与关系数据库之间传输数据的工具。 | Hadoop生态系统的一部分 |
| 11 | 数据可视化 | Tableau | 数据可视化工具,用于创建和共享交互式和可视化的图表。 | 独立技术栈,支持多种数据源 |
| 12 | 数据治理 | Apache Atlas | 基于Hadoop的数据治理和元数据管理平台。 | Hadoop生态系统的一部分 |
这个介绍展示了大数据文件管理领域的一些常用技术和对应的技术栈管理情况,实际应用中,可以根据项目需求选择合适的技术进行组合和优化,希望这个介绍对您有所帮助。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/700050.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复