


爬虫与大数据的关系

爬虫,也被称为网络爬虫或者蜘蛛,是一种自动浏览万维网的网络机器人,其主要任务是按照一定的规则,自动地抓取网页信息,大数据则是指在传统数据处理应用软件不足以处理的大或复杂数据集。
爬虫在大数据中的应用非常广泛,它们可以自动化地收集和处理大量的数据,为大数据分析提供基础,以下是爬虫与大数据的一些主要关系:
1、数据收集:爬虫可以从互联网上自动收集大量的数据,这些数据可以是文本、图片、视频等各种形式,为大数据分析提供了丰富的原始数据。
2、数据清洗:爬虫在收集数据的过程中,可以对数据进行初步的清洗和整理,去除无效和重复的数据,提高数据的质量和可用性。
3、数据分析:爬虫收集的数据可以直接用于大数据分析,通过数据挖掘和机器学习等技术,可以从数据中发现有价值的信息和知识。
4、数据更新:爬虫可以定期或者实时地从互联网上收集新的数据,保证大数据分析的数据是最新的。
开启网站反爬虫中的“其他爬虫”会影响网页的浏览速度吗?

网站反爬虫是一种保护网站资源不被恶意抓取的技术手段,开启网站反爬虫中的“其他爬虫”可能会影响网页的浏览速度,具体影响程度取决于多种因素。
1、服务器压力:如果有大量的爬虫同时访问网站,可能会给服务器带来很大的压力,导致服务器响应变慢,从而影响网页的浏览速度。
2、带宽占用:爬虫在抓取网页数据时,会占用大量的网络带宽,如果带宽被大量占用,可能会导致正常用户的网络速度变慢。
3、反爬虫策略:网站的反爬虫策略也会影响网页的浏览速度,一些网站会采取限制爬虫访问频率、限制单个IP的访问量等策略,这些策略可能会影响爬虫的抓取效率,从而影响网页的浏览速度。
4、网站设计:如果网站的设计和布局不合理,可能会导致爬虫在抓取数据时需要花费更多的时间,从而影响网页的浏览速度。
开启网站反爬虫中的“其他爬虫”可能会影响网页的浏览速度,但具体影响程度取决于多种因素。
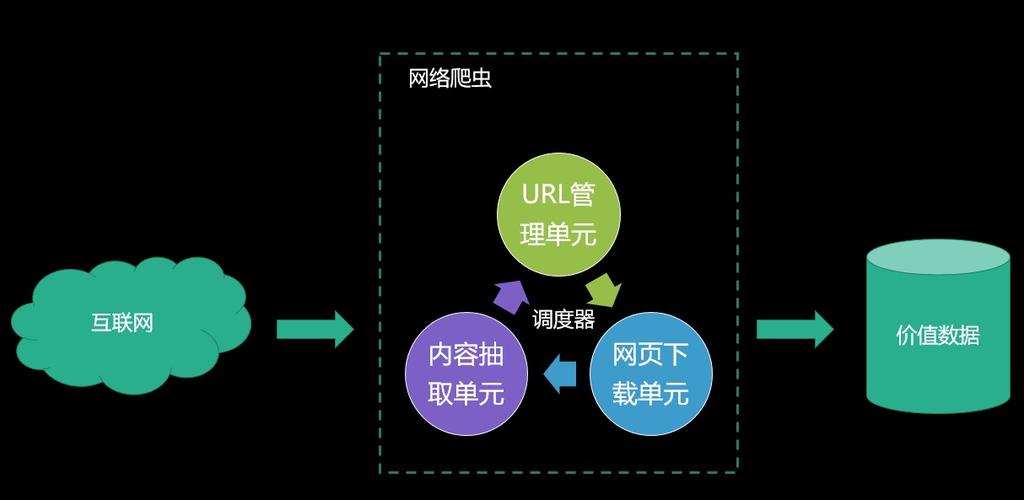
下面是一个介绍,概述了爬虫与大数据的关系,并针对“开启网站反爬虫中的‘其他爬虫’会影响网页的浏览速度吗?”这一问题提供了答案。
| 关系/问题 | 描述/答案 |
| 爬虫与大数据的关系 | 爬虫是大数据时代获取数据的重要手段之一,通过爬虫可以自动化收集海量的网页数据,为大数据分析提供数据源。 |
| 开启反爬虫机制的目的 | 保护网站数据安全,防止数据被滥用;减轻服务器负载,维护网站正常运行。 |
| “其他爬虫”的定义 | 通常指非目标用户正常访问请求的自动化抓取工具,例如批量数据抓取的爬虫。 |
| 开启反爬虫对网页浏览速度的影响 | 可能会有一定影响,具体如下: |
| 1.正面影响 | 通过限制非法爬虫的访问,降低服务器压力,从而可能提升合法用户的访问速度。 |
| 2.负面影响 | 反爬虫机制自身也需要消耗服务器资源,如频繁验证用户行为、检查请求特征等,可能会在一定程度上增加网页响应时间。 |
| 开启反爬虫可能会对网页浏览速度产生双重影响,但合理的反爬虫策略会尽量减少对合法用户访问速度的负面影响。 |
一个设计良好的反爬虫机制会尽量在不妨碍合法用户正常访问的前提下,对非法爬虫进行有效的拦截,这样的策略可以在保护网站内容的同时,维持良好的用户体验。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/699479.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复