


大数据自适应方向是指在大数据领域中,通过自适应算法和技术来处理和分析大规模数据的一种方法,这种方法可以根据数据的特点和需求,自动调整算法的参数和结构,以提高数据处理的效率和准确性。
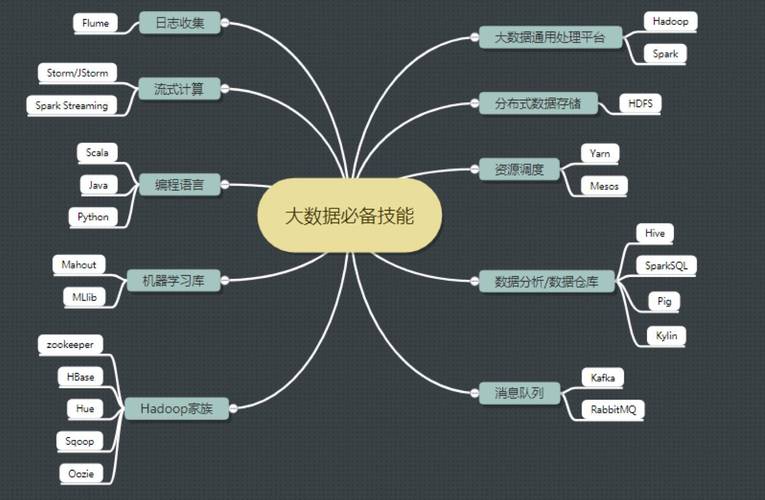

以下是大数据自适应方向的一些主要技术和方法:
1、自适应聚类算法:
Kmeans聚类算法:通过不断迭代更新聚类中心,将数据点分配到最近的聚类中心,直到满足停止条件。
DBSCAN聚类算法:根据数据点的密度和距离关系,自动确定聚类的边界和核心点。
2、自适应特征选择算法:
基于信息增益的特征选择算法:通过计算每个特征的信息增益,选择具有最大信息增益的特征子集。
基于互信息的特征选择算法:通过计算特征之间的互信息,选择具有最大互信息的特征子集。
3、自适应降维算法:
主成分分析(PCA):通过线性变换将高维数据映射到低维空间,保留最重要的特征。
tSNE:通过非线性变换将高维数据映射到低维空间,保持数据点之间的相似性。
4、自适应模型选择算法:
网格搜索:通过遍历给定的参数组合,选择最优的模型参数。
随机搜索:通过随机选择参数组合,进行多次训练和评估,选择最优的模型参数。
5、自适应学习率调整算法:

梯度下降法:通过计算梯度来更新模型参数,根据梯度的大小调整学习率。
自适应学习率优化算法(如Adam、RMSProp等):根据模型的梯度信息和历史梯度信息,动态调整学习率。
6、自适应数据采样算法:
重采样技术:通过对数据集进行有放回或无放回的抽样,平衡数据集的类别分布。
过采样技术:通过对少数类别的数据进行复制或生成新样本,增加少数类别的样本数量。
7、自适应并行计算算法:
MapReduce:将大规模数据集分割成多个小数据集,并行处理每个小数据集,最后合并结果。
Spark:通过将数据分布在多个节点上,并行执行任务,提高数据处理的速度和效率。
下面是一个关于“大数据 方向_自适应方向”的介绍示例:
| 序号 | 方向名称 | 方向描述 | 应用场景 |
| 1 | 数据采集与分析 | 采集海量数据,并通过数据分析技术提取有价值的信息 | 互联网搜索、用户行为分析、商业智能 |
| 2 | 机器学习与人工智能 | 利用机器学习算法和人工智能技术对数据进行智能处理和预测 | 金融风控、智能语音助手、自动驾驶 |
| 3 | 大数据可视化 | 将数据以图表、图像等形式展示出来,以便更好地理解数据背后的规律 | 数据报告、商业决策、城市规划 |
| 4 | 云计算与大数据 | 利用云计算技术进行大数据的存储、处理和分析 | 企业数据管理、大规模并行计算、在线教育 |
| 5 | 网络安全与隐私保护 | 保护大数据在存储、传输和使用过程中的安全性和用户隐私 | 金融、医疗、政府数据安全 |
| 6 | 数据挖掘与知识发现 | 从大量数据中挖掘出潜在的模式和知识 | 电子商务推荐系统、生物信息学、社会网络分析 |
| 7 | 区块链技术 | 利用区块链技术实现数据的安全、透明和去中心化 | 数字货币、供应链管理、版权保护 |
| 8 | 物联网与大数据 | 结合物联网技术,实现大数据在各个领域的应用 | 智能家居、智慧城市、工业自动化 |
| 9 | 边缘计算 | 在数据源附近进行数据处理,减少数据传输延迟和带宽需求 | 智能交通、远程医疗、智能工厂 |
| 10 | 数据治理与质量控制 | 对数据进行标准化、清洗和质量管理,以确保数据的可靠性和可用性 | 企业数据管理、政府数据开放、科研数据共享 |
这个介绍列举了大数据领域的10个主要方向,以及它们对应的描述和应用场景,希望这个介绍能对您有所帮助。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/698377.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复