

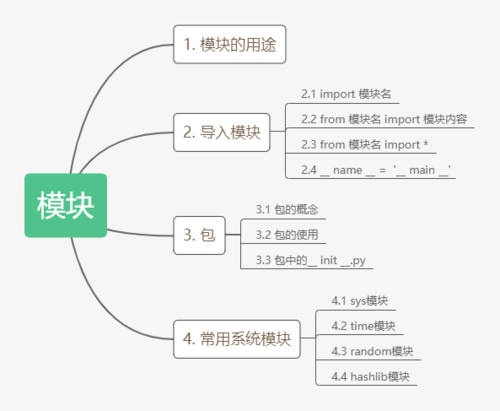
Python机器学习模块主要包括以下几个部分:
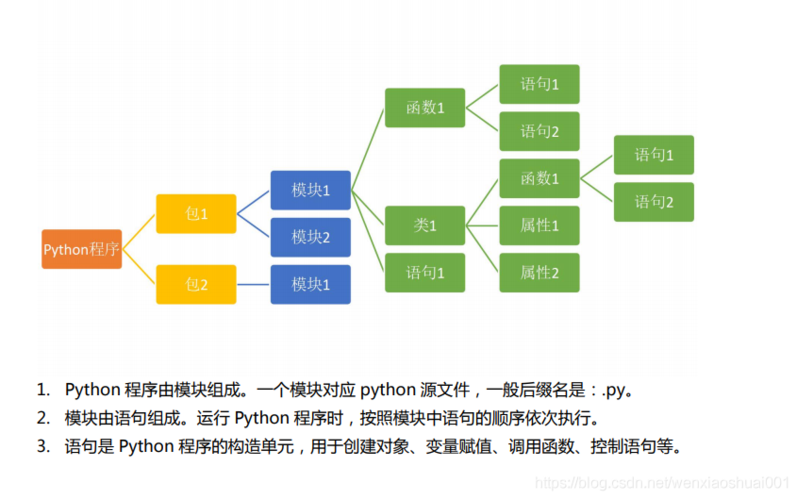

1、数据处理
pandas:用于数据清洗和数据分析
numpy:用于数值计算
scipy:科学计算库,包含统计、优化等功能
matplotlib:绘图库
seaborn:基于matplotlib的数据可视化库
2、特征工程
sklearn.feature_extraction:特征提取方法,如PCA、LDA等
sklearn.preprocessing:数据预处理方法,如归一化、标准化等
3、模型选择与评估
sklearn.model_selection:模型选择方法,如交叉验证、网格搜索等
sklearn.metrics:评估指标,如准确率、召回率等
4、分类算法
sklearn.linear_model:线性分类器,如逻辑回归、支持向量机等

sklearn.tree:决策树分类器,如随机森林、梯度提升树等
sklearn.ensemble:集成学习算法,如Bagging、Boosting等
sklearn.naive_bayes:朴素贝叶斯分类器
sklearn.svm:支持向量机分类器
5、回归算法
sklearn.linear_model:线性回归模型,如岭回归、Lasso回归等
sklearn.tree:决策树回归模型,如CART回归树等
sklearn.ensemble:集成学习算法,如Bagging回归、Boosting回归等
sklearn.neural_network:神经网络模型,如多层感知机、卷积神经网络等
6、聚类算法
sklearn.cluster:聚类算法,如Kmeans、层次聚类等
7、降维算法
sklearn.decomposition:降维算法,如主成分分析(PCA)、线性判别分析(LDA)等
8、关联规则挖掘
mlxtend:关联规则挖掘库,包含Apriori、FPgrowth等算法
9、时间序列分析
statsmodels:统计模型库,包含ARIMA、VAR等模型
pmdarima:基于statsmodels的时间序列分析库,包含季节性分解、自回归条件异方差等模型
下面是一个简化的介绍,列出了一些Python中常用的机器学习模块及其简短描述:
| 模块名 | 描述 |
scikitlearn | 强大的机器学习库,提供了一系列监督和非监督学习算法。 |
TensorFlow | 由Google开发的开源机器学习框架,适用于深度学习应用。 |
Keras | 在TensorFlow之上的高级神经网络API,用户友好,模块化,可扩展。 |
PyTorch | 由Facebook开发的开源机器学习库,同样适用于深度学习,易于使用。 |
Pandas | 数据分析和操作库,提供数据结构DataFrame,适用于数据处理和清洗。 |
NumPy | 提供多维数组对象和一系列处理数组的函数,是科学计算的基石。 |
Matplotlib | 强大的数据可视化库,用于绘制图表和图形。 |
Seaborn | 基于Matplotlib的数据可视化库,提供更美观和统计导向的图表。 |
XGBoost | 高性能的梯度提升框架,用于在机器学习中实现增强学习算法。 |
LightGBM | 微软提供的梯度提升框架,速度快效率高,占用内存少。 |
scipy | 用于科学和工程计算的库,提供了许多机器学习算法的底层优化功能。 |
statsmodels | 统计建模和假设检验的工具包,适用于探索数据统计特性。 |
Plotly | 用于创建交互式图表和数据可视化的库。 |
OpenCV | 开源计算机视觉库,包含机器学习模块,用于图像处理和识别。 |
这个介绍只是一个概览,每个模块都有其独特的功能和用途,可以根据具体的机器学习项目需求选择合适的模块。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/697083.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复