


简介
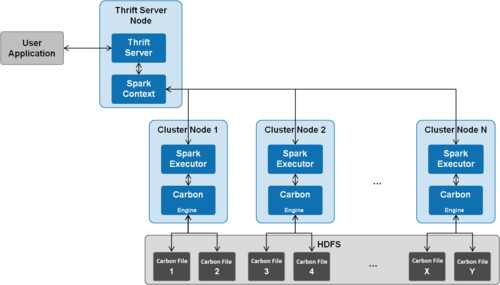

CarbonData是一个开源的、面向列的、分布式的数据存储格式,用于在Apache Spark上处理大规模数据,它提供了高效的数据压缩、查询优化和快速数据访问,适用于大数据分析场景,本文将介绍如何使用CarbonData,包括如何创建表、插入数据、执行查询等操作。
环境准备
在使用CarbonData之前,需要确保已经安装了以下环境:
1、Apache Spark:CarbonData是基于Apache Spark的,因此需要安装Spark环境,推荐使用2.x版本。
2、Scala:CarbonData是用Scala编写的,因此需要安装Scala环境。
3、IDE:推荐使用IntelliJ IDEA或者Eclipse进行开发和调试。
创建表
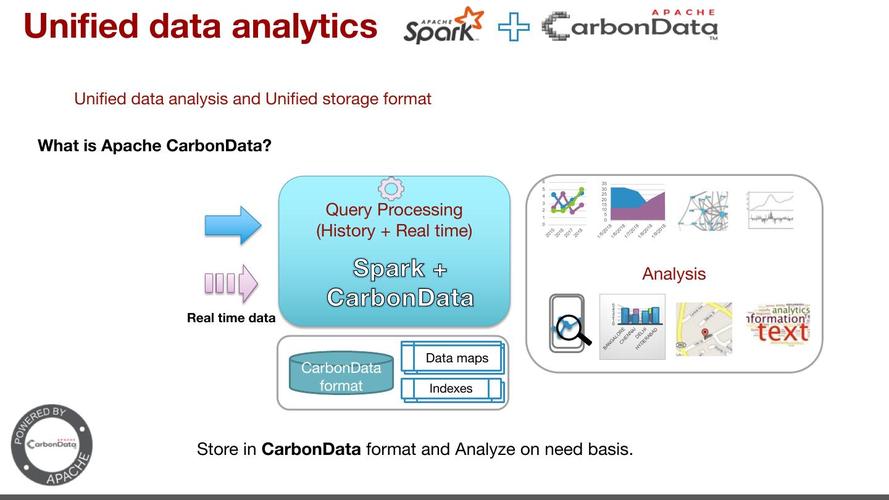
要使用CarbonData,首先需要创建一个表,以下是创建表的步骤:
1、导入相关依赖:在项目的build.sbt文件中,添加以下依赖:
libraryDependencies += "org.apache.carbondata" % "carbondatacore" % "1.6.0"
2、定义数据模型:创建一个case class,用于定义表的结构,创建一个名为Person的类:
case class Person(name: String, age: Int, gender: String)
3、注册数据源:使用CarbonContext的registerDataFrame方法,注册一个DataFrame作为数据源,创建一个包含Person对象的DataFrame:
import org.apache.carbondata.common.annotations._
import org.apache.carbondata.core.constants.CarbonCommonConstants
import org.apache.carbondata.core.util.CarbonUtil
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types._
val spark = SparkSession.builder().appName("CarbonDataExample").getOrCreate()
val personDF = spark.createDataFrame(Seq(Person("张三", 25, "男"), Person("李四", 30, "女"))).toDF("name", "age", "gender")
personDF.show()
val carbonContext = new CarbonContext(spark)
carbonContext.registerDataFrame(personDF, "person") 4、创建表:使用CarbonContext的sql方法,执行SQL语句创建表,创建一个名为person_info的表:
carbonContext.sql("CREATE TABLE person_info (name STRING, age INT, gender STRING) STORED AS carbondata") 插入数据
创建好表后,可以使用CarbonContext的write方法,将数据插入到表中,以下是插入数据的步骤:
1、获取表的schema:使用CarbonContext的getSchema方法,获取表的结构信息。
val schema = carbonContext.getSchema("person_info")
println(schema) 2、插入数据:使用CarbonContext的write方法,将数据插入到表中。
val data = Seq(Person("张三", 25, "男"), Person("李四", 30, "女"))
carbonContext.write("person_info", data) 查询数据
插入数据后,可以使用CarbonContext的sql方法,执行SQL语句查询数据,以下是查询数据的步骤:
1、执行查询:使用CarbonContext的sql方法,执行SQL语句查询数据,查询所有记录:
val result = carbonContext.sql("SELECT * FROM person_info")
result.show() 2、过滤数据:可以使用SQL语句中的WHERE子句,对查询结果进行过滤,查询年龄大于等于30的记录:
val result = carbonContext.sql("SELECT * FROM person_info WHERE age >= 30")
result.show() FAQs
Q1:如何在Spark中使用多个CarbonData表进行join操作?
A1:在Spark中,可以使用CarbonData提供的API进行多个表的join操作,需要确保这些表都已经创建并注册到CarbonContext中,可以使用如下代码进行join操作:
val table1 = carbonContext.table("table1") // 替换为实际的表名和别名(如果有)
val table2 = carbonContext.table("table2") // 替换为实际的表名和别名(如果有)
val result = table1.join(table2, table1("id") === table2("id")) // 替换为实际的join条件和列名(如果有)
result.show() // 显示查询结果 Q2:如何更新CarbonData表中的数据?
A2:要更新CarbonData表中的数据,可以使用CarbonContext的write方法,将更新后的数据写入表中,假设有一个名为person_info的表,现在需要更新其中一条记录的年龄为26,可以执行如下代码:
val updatedData = Seq(Person("张三", 26, "男")) // 替换为实际的更新后的数据集合(如果有)
carbonContext.write("person_info", updatedData) // 将更新后的数据写入表中,原有的其他记录不会被覆盖或删除(如果存在) 下面是一个关于如何使用CarbonData的简单介绍,其中包括了一些基本的使用步骤和概念。
| 步骤 | 操作 | 描述 |
| 1 | 安装和配置 | 确保你的系统已经安装了Hadoop和Spark环境,然后安装CarbonData,配置相应的Spark和Hadoop配置文件。 |
| 2 | 创建表 | 使用CarbonData提供的API或命令行工具创建表。 |
| 语法 | CREATE TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type , ...)] STORED BY 'carbondata' | 创建一个CarbonData表 |
| 示例 | CREATE TABLE carbontable (ID INT, name STRING, age INT) STORED BY 'carbondata' | 创建一个名为carbontable的表 |
| 3 | 数据加载 | 将数据加载到已经创建的CarbonData表中。 |
| 语法 | LOAD DATA [LOCAL] INPATH 'path' INTO TABLE [db_name.]table_name | 加载数据到表中 |
| 示例 | LOAD DATA INPATH '/path/to/data.csv' INTO TABLE carbontable | 从HDFS加载一个CSV文件到carbontable |
| 4 | 查询数据 | 使用Spark SQL查询CarbonData表中的数据。 |
| 语法 | SELECT * FROM [db_name.]table_name WHERE ... | 查询表中的数据 |
| 示例 | SELECT name, age FROM carbontable WHERE age > 30 | 查询年龄大于30的所有人的姓名和年龄 |
| 5 | 更新和删除 | CarbonData支持数据的更新和删除操作。 |
| 语法 | UPDATE [db_name.]table_name SET col1 = value1 WHERE ...DELETE FROM [db_name.]table_name WHERE ... | 更新或删除表中的数据 |
| 示例 | UPDATE carbontable SET age = 40 WHERE ID = 1 | 更新ID为1的记录的年龄 |
| 6 | 优化表 | 为了提高查询性能,可以执行表的优化操作。 |
| 语法 | OPTIMIZE TABLE [db_name.]table_name | 优化表 |
| 示例 | OPTIMIZE TABLE carbontable | 对carbontable执行优化 |
| 7 | 查看元数据 | 可以查看表的元数据信息,了解其结构和存储情况。 |
| 语法 | DESCRIBE FORMATTED [db_name.]table_name | 查看表的详细信息 |
| 示例 | DESCRIBE FORMATTED carbontable | 查看carbontable的详细信息 |
请注意,上述介绍只是一个简化的示例,实际使用时,你需要根据你的具体需求和数据情况调整命令和参数,CarbonData的使用也涉及到调优和性能优化等更高级的主题。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/694968.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复