


在机器学习中,偏度和峰度是两个重要的统计概念,它们描述了数据分布的形状,偏度(skewness)衡量的是数据分布的不对称性,而峰度(kurtosis)则衡量的是数据分布的尖锐程度,这两个指标可以帮助我们更好地理解数据的分布特性,从而为机器学习模型的选择和优化提供参考。

1. 偏度的计算和解释
偏度是衡量数据分布不对称性的统计量,其值可以是正数、负数或零,如果数据的分布是对称的,那么偏度的值就是零,如果数据的分布是右偏的,那么偏度的值为正数;如果数据的分布是左偏的,那么偏度的值为负数。
偏度的计算公式为:
Skewness = E[((X μ) / σ)^3]
X是数据,μ是数据的均值,σ是数据的标准差。
2. 峰度的计算和解释
峰度是衡量数据分布尖锐程度的统计量,其值可以是正数、负数或零,如果数据的分布是尖峰的,那么峰度的值为正数;如果数据的分布是扁平的,那么峰度的值为负数;如果数据的分布是标准的(即高斯分布),那么峰度的值为零。
峰度的计算公式为:
Kurtosis = E[((X μ) / σ)^4] 3
X是数据,μ是数据的均值,σ是数据的标准差。
3. 偏度和峰度的应用
在机器学习中,偏度和峰度可以用来帮助我们选择合适的模型和优化模型的性能。
如果数据的分布是左偏的,那么我们可能需要选择一个对异常值不敏感的模型,如决策树或随机森林。
如果数据的分布是右偏的,那么我们可能需要选择一个能够捕捉到数据尾部信息的模型,如逻辑回归或支持向量机。
如果数据的分布是尖峰的,那么我们可能需要选择一个能够捕捉到数据高频波动的模型,如时间序列分析模型。
如果数据的分布是扁平的,那么我们可能需要选择一个能够捕捉到数据低频波动的模型,如主成分分析模型。
我们还可以通过调整模型的参数来改变模型对数据分布的敏感性,我们可以增加决策树的最大深度来提高模型对异常值的敏感度;我们可以增加逻辑回归的正则化系数来降低模型对异常值的敏感度。
4. 偏度和峰度的可视化
我们可以使用直方图、箱线图等工具来可视化数据的偏度和峰度,我们可以画出数据的直方图,然后观察直方图的形状来判断数据的偏度和峰度,我们也可以使用Python的seaborn库来画出数据的箱线图,然后观察箱线图的形状来判断数据的偏度和峰度。
5. 偏度和峰度的计算实例
假设我们有一组数据,其均值为10,标准差为2,我们可以使用上述公式来计算这组数据的偏度和峰度。
偏度的计算过程如下:
Skewness = E[((X μ) / σ)^3] = E[(X μ)^3 / σ^3] = E[(X μ)^3] / σ^3 = (10 10)^3 / (2)^3 = 0 / 8 = 0
这组数据的偏度为0,说明这组数据是对称的。
峰度的计算过程如下:
Kurtosis = E[((X μ) / σ)^4] 3 = E[(X μ)^4 / σ^4] 3 = E[(X μ)^4] / σ^4 3 = (10 10)^4 / (2)^4 3 = 0 / 16 3 = 2.75
这组数据的峰度为2.75,说明这组数据的分布比标准分布更扁平。
FAQs
Q1: 偏度和峰度有什么区别?
A1: 偏度和峰度都是描述数据分布形状的统计量,但它们关注的是不同的方面,偏度衡量的是数据分布的不对称性,而峰度衡量的是数据分布的尖锐程度。
Q2: 如果我知道了我的数据是左偏的,我应该如何选择机器学习模型?
A2: 如果数据是左偏的,那么你可能需要选择一个对异常值不敏感的模型,如决策树或随机森林,这是因为这些模型可以在一定程度上忽略数据尾部的信息,从而减少对异常值的影响。
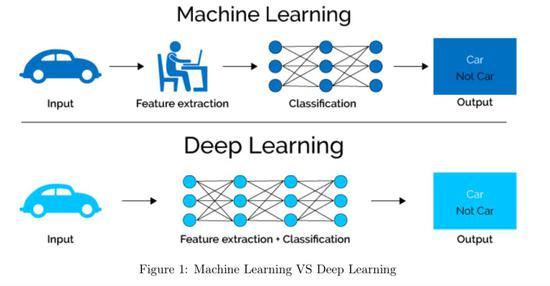
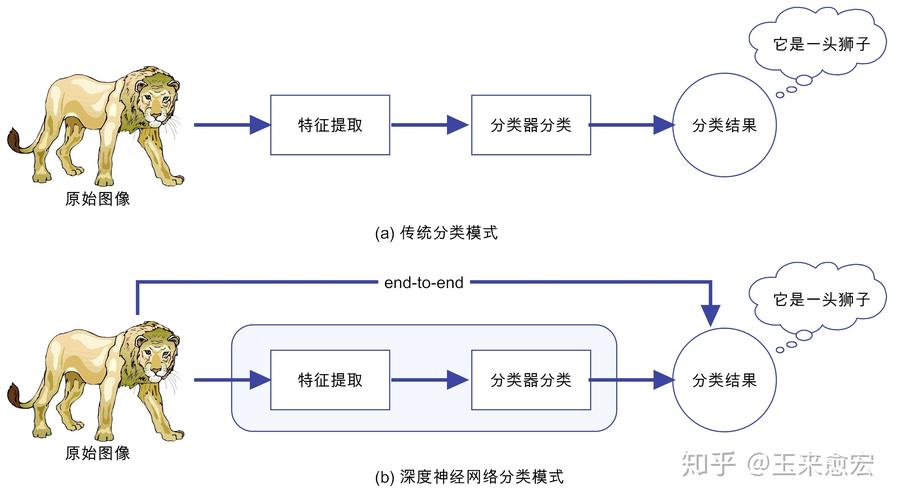
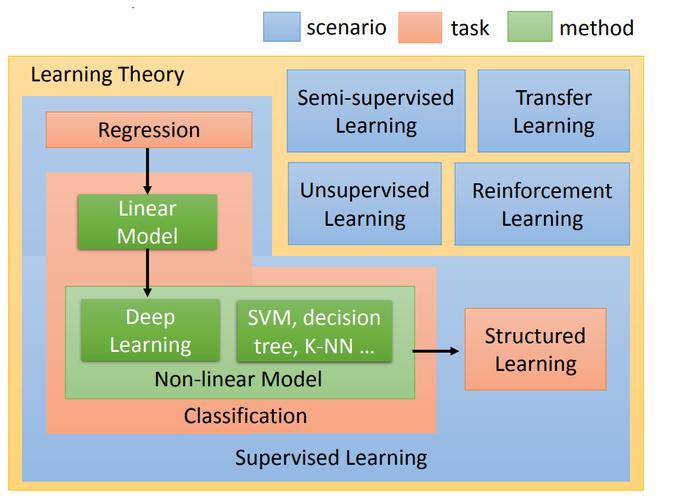
下面是一个简化的介绍,概述了偏度、峰度在机器学习中的意义,以及端到端学习在机器学习场景中的应用:
| 统计量/概念 | 定义 | 在机器学习中的意义 | 端到端学习场景中的应用 |
| 偏度(Skewness) | 描述数据分布不对称性的统计量,正态分布的偏度为0,偏度大于0表示右偏,小于0表示左偏。 | 反映数据分布的扭曲程度,影响模型预测的准确性,非对称的数据分布可能需要特别的预处理或模型选择。 | 在端到端学习中,偏度可以作为数据预处理的一个指标,帮助选择或调整模型以适应数据的偏斜。 |
| 峰度(Kurtosis) | 描述数据分布尖峭或平坦程度的统计量,正态分布的峰度为3,峰度大于3表示分布更尖锐,小于3表示分布更平坦。 | 反映数据分布的尖峭或厚尾特征,对异常值敏感,影响模型的鲁棒性。 | 在端到端学习中,峰度可以帮助识别数据中异常值的影响,从而指导模型设计,例如选择能够抵抗异常值的算法。 |
| 端到端学习(EndtoEnd Learning) | 一种学习方法,直接从原始输入数据到最终预测结果,不需要手动进行特征提取等预处理步骤。 | 允许模型自动学习数据特征,简化流程,减少人为错误,提高学习效率。 | 偏度和峰度可以作为模型评估的一部分,帮助理解端到端模型在整个数据分布上的表现,进而优化模型结构或训练过程。 |
通过这个介绍,我们可以快速了解偏度、峰度在机器学习中的重要性,以及它们在端到端学习场景中如何帮助改进模型的性能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/692276.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复