


在软件开发中,评分代码是一种用于评估和比较不同算法或模型性能的工具,它可以帮助开发者选择最佳的算法或模型,以提高软件的性能和效率,评分代码通常包括以下几个步骤:
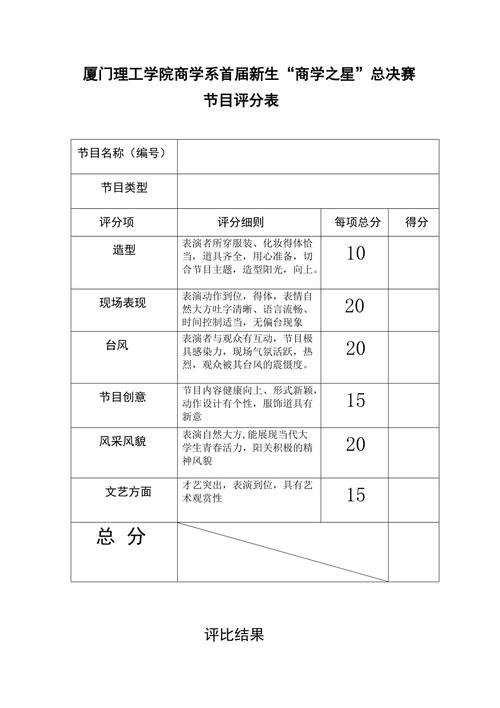

1、数据准备:需要收集和整理用于评估的数据,这些数据可以是实际的用户行为数据,也可以是模拟的数据,数据的质量和数量对评分结果的准确性有很大影响。
2、模型训练:使用收集到的数据,训练不同的算法或模型,这个过程可能需要多次迭代,以优化模型的参数和结构。
3、模型评估:使用特定的评估指标,对训练好的模型进行评估,这些指标可以包括准确率、召回率、F1分数等,评估结果可以帮助开发者了解模型的优点和缺点。
4、模型比较:将不同模型的评估结果进行比较,选择最佳的模型,这个过程可能需要使用统计方法,如t检验或ANOVA分析。
5、模型优化:根据评估结果,对模型进行进一步的优化,这可能包括调整模型的参数,或者尝试新的算法或模型。
6、模型部署:将优化后的模型部署到生产环境中,这个过程可能需要进行一些额外的测试,以确保模型的稳定性和性能。
在实际应用中,评分代码可能会遇到一些问题,数据可能存在偏差,导致评估结果不准确;模型可能存在过拟合或欠拟合的问题;评估指标可能无法全面反映模型的性能等,为了解决这些问题,开发者需要不断学习和实践,提高自己的技能和经验。
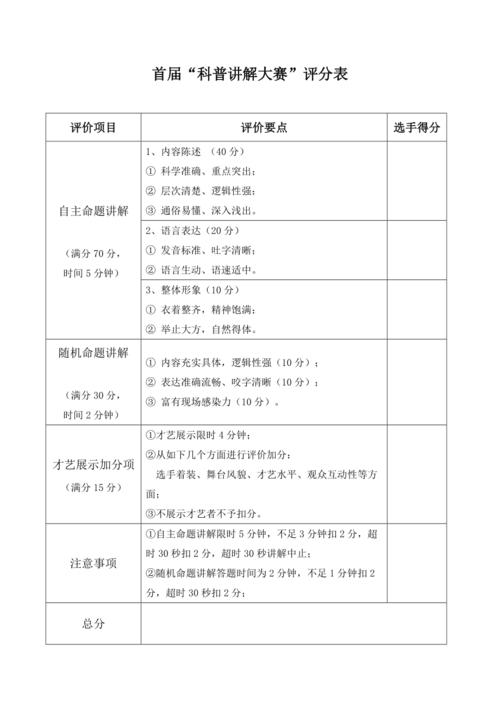
以下是一些常见的评分代码问题和解答:
问题1:如何选择合适的评估指标?
答:选择合适的评估指标取决于具体的应用场景和目标,如果目标是精确地预测每个样本的结果,那么可以选择准确率作为评估指标;如果目标是找出所有的重要样本,那么可以选择召回率作为评估指标;如果既关心精确率也关心召回率,那么可以选择F1分数作为评估指标,还可以根据业务需求,自定义评估指标。
问题2:如何处理数据偏差?
答:处理数据偏差的方法有很多,可以通过收集更多的数据,来减少数据偏差的影响,可以使用一些统计方法,如标准化或归一化,来消除数据偏差,还可以通过调整模型的参数,来适应数据偏差,可以通过交叉验证等方法,来验证模型的泛化能力。
评分代码是软件开发中非常重要的一部分,通过有效的评分代码,开发者可以更好地理解和改进自己的算法或模型,从而提高软件的性能和效率。
相关问答FAQs
问题1:如何选择合适的评估指标?
答:选择合适的评估指标取决于具体的应用场景和目标,如果目标是精确地预测每个样本的结果,那么可以选择准确率作为评估指标;如果目标是找出所有的重要样本,那么可以选择召回率作为评估指标;如果既关心精确率也关心召回率,那么可以选择F1分数作为评估指标,还可以根据业务需求,自定义评估指标。
问题2:如何处理数据偏差?
答:处理数据偏差的方法有很多,可以通过收集更多的数据,来减少数据偏差的影响,可以使用一些统计方法,如标准化或归一化,来消除数据偏差,还可以通过调整模型的参数,来适应数据偏差,可以通过交叉验证等方法,来验证模型的泛化能力。
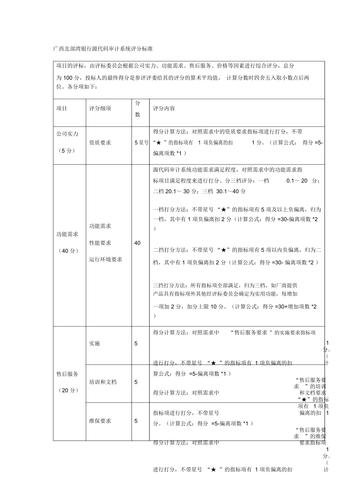
如果您希望将“评分代码_评分”这一概念制作成介绍,下面是一个简单的示例,这个介绍可以是用来记录不同代码对应的评分值。
| 评分代码 | 评分描述 |
| A+ | 95100 |
| A | 9094 |
| A | 8589 |
| B+ | 8084 |
| B | 7579 |
| B | 7074 |
| C+ | 6569 |
| C | 6064 |
| C | 5559 |
| D | 5054 |
| F |
这个介绍中,左侧列是评分代码,表示不同的评分等级;右侧列是对应的评分描述,即分数范围,根据具体的应用场景,评分代码和分数范围可以根据实际需要进行调整。
如果您需要的是另一种格式的介绍或者有其他特定的要求,请提供更多的信息。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/691658.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复