


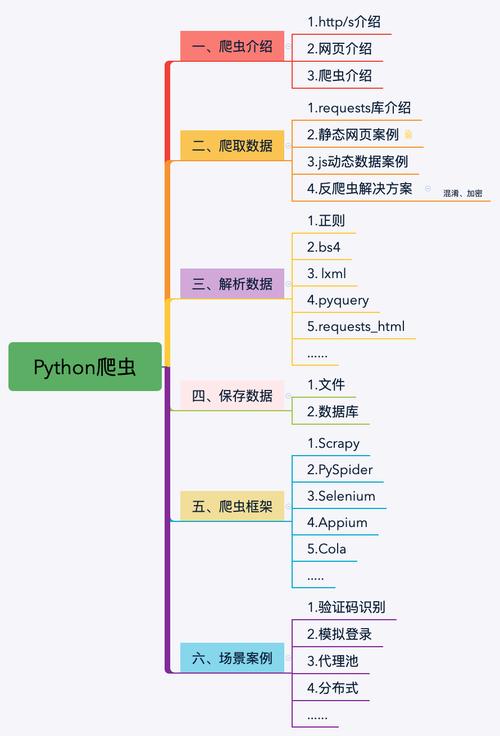
Python爬虫是一种自动化获取网络信息的工具,通常使用Python编程语言来实现,下面是一些Python爬虫常用的用法技巧和基本用法:

1、请求网页数据
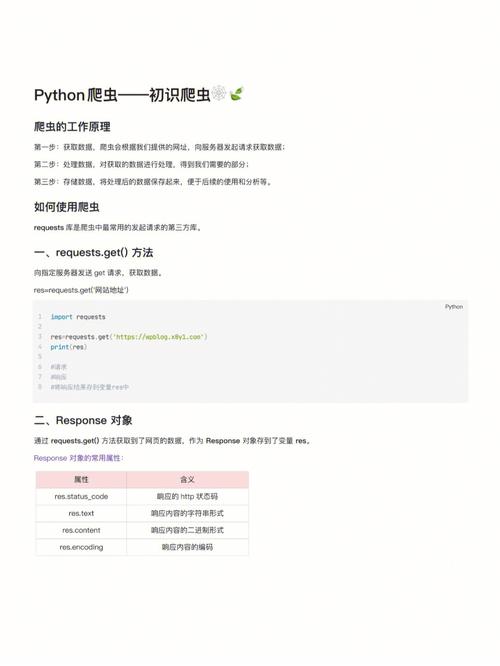
使用requests库发送HTTP请求并获取响应数据。
“`python
import requests
url = "https://example.com"
response = requests.get(url)
content = response.text
“`
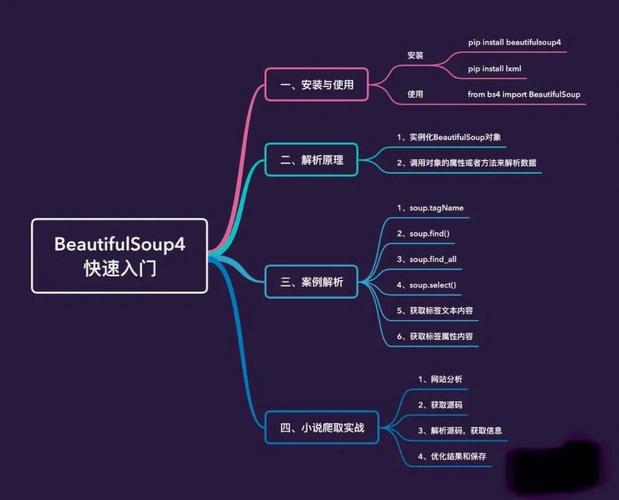
2、解析网页数据
使用BeautifulSoup库解析HTML页面并提取所需信息。
“`python
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, "html.parser")
title = soup.title.string
“`
3、处理分页和翻页
通过分析网页的分页结构,循环发送请求并提取每个页面的数据。
“`python
for page in range(1, 10):
url = f"https://example.com/page/{page}"
response = requests.get(url)
content = response.text
# 解析和提取数据的逻辑
“`
4、处理重试和异常
使用tryexcept语句处理请求失败或解析错误等异常情况,并进行相应的重试操作。
“`python
for page in range(1, 10):
try:
url = f"https://example.com/page/{page}"
response = requests.get(url)
content = response.text
# 解析和提取数据的逻辑
except requests.exceptions.RequestException as e:
print(f"请求异常: {e}")
# 重试逻辑
“`
5、存储数据
根据需求将爬取到的数据存储到文件、数据库或进行进一步处理。
“`python
with open("output.txt", "a") as file:
file.write(f"标题: {title}
")
“`
6、使用代理和伪装
使用代理IP和伪装UserAgent来绕过网站的反爬虫机制。
“`python
headers = {"UserAgent": "Mozilla/5.0"}
proxies = {"http": "http://proxy.example.com:8080"}
response = requests.get(url, headers=headers, proxies=proxies)
“`
7、使用正则表达式
使用re模块中的正则表达式来匹配和提取特定的文本模式。
“`python
import re
pattern = r"d+.d+|d+"
prices = re.findall(pattern, content)
“`
8、使用XPath和CSS选择器
使用lxml库结合XPath或CSS选择器来精确定位和提取数据。
“`python
from lxml import html
tree = html.fromstring(content)
titles = tree.xpath("//h2/a/text()")
“`
9、使用Selenium处理动态内容
使用selenium库模拟浏览器行为,处理JavaScript生成的动态内容。
“`python
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(url)
dynamic_content = driver.find_element_by_id("dynamic").text
“`
10、遵守爬虫道德规范
尊重网站的Robots协议,合理设置抓取频率,不滥用爬虫资源。
下面是一个关于Python爬虫基本用法的介绍,包括了一些常用的用法技巧:
| 技巧/用法 | 描述 | 代码示例 |
| 请求网页 | 使用requests库发送HTTP请求 | import requests |
| 解析HTML | 使用BeautifulSoup库解析HTML内容 | from bs4 import BeautifulSoup |
| 查找标签 | 使用BeautifulSoup查找HTML标签 | title_tag = soup.find('title') |
| 提取数据 | 从标签中提取文本或属性 | title_text = title_tag.get_text() |
| 遍历循环 | 遍历标签列表提取数据 | for link in links: |
| 用户代理 | 设置UserAgent来伪装请求 | headers = {'UserAgent': 'Mozilla/5.0'} |
| 异常处理 | 捕捉和处理请求异常 | try: |
| 防止封IP | 设置请求间隔,避免频繁请求 | import time |
| 保存数据 | 将提取的数据保存到文件 | with open('data.txt', 'w') as f: |
| 处理Cookies | 使用requests库处理Cookies | response = requests.get(url) |
| 会话维持 | 使用requests.Session()维持会话 | with requests.Session() as session: |
| 表单提交 | 使用requests库提交表单 | data = {'username': 'user', 'password': 'pass'} |
| 处理Ajax请求 | 获取动态加载的内容 | response = requests.get(url, params={'ajax': 'true'}) |
| 代理设置 | 设置代理服务器 | proxies = {'http': 'http://10.10.1.10:3128', 'https': 'http://10.10.1.10:1080'} |
| SSL证书验证 | 对于HTTPS请求,可选择忽略SSL证书验证 | response = requests.get(url, verify=False) |
请注意,以上代码只是作为示例提供,实际使用时可能需要根据具体情况进行调整,在使用爬虫时,应当遵循网站的robots.txt文件规定,尊重版权和隐私,合法合规地采集数据。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/689555.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复