


爬虫数据库去重与uid配置
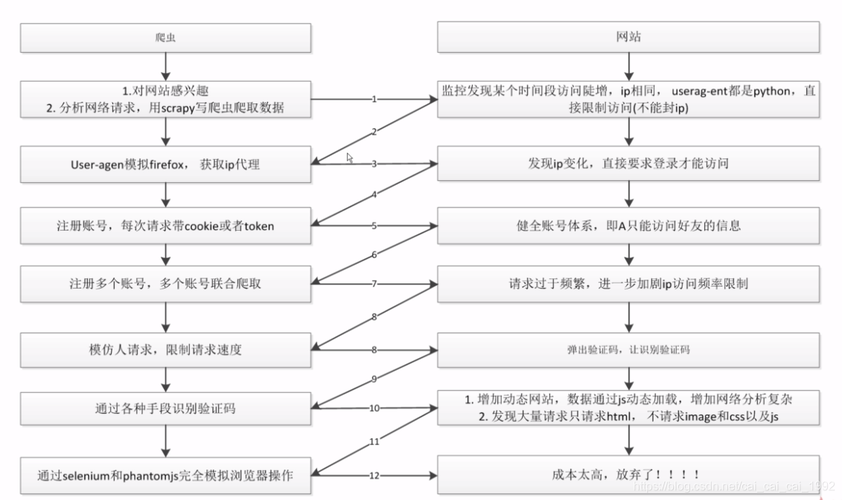

在网络数据采集(即爬虫)的过程中,数据去重和用户识别(uid配置)是两个重要的环节,它们不仅有助于提高数据质量,还能增强网站的安全性,防止恶意爬虫的攻击。
数据去重的重要性
数据去重是指在数据采集过程中排除重复的数据记录,由于网络爬虫可能会多次访问同一网页或资源,因此很容易收集到重复的信息,数据去重可以确保数据库中存储的是唯一的、最新的信息,这对于数据分析的准确性至关重要。
实现方法
1、基于内容去重:比较数据记录的内容,如果两条记录完全相同,则认为它们是重复的。
2、基于哈希去重:为每条数据记录生成一个哈希值,通过比较哈希值来快速判断数据是否重复。
3、基于时间戳去重:检查数据的更新时间,只保留最新更新的记录。
uid配置的作用
uid(用户识别码)配置是指为每个访问网站的用户分配一个唯一的标识符,这可以帮助网站管理员追踪用户行为,同时区分正常用户和爬虫程序。
实现方法
1、IP地址跟踪:记录每个访问者的IP地址,但这种方法可能会因为IP地址的动态分配而不够准确。
2、Cookie追踪:通过在用户浏览器中设置Cookie来追踪用户,但这可能会受到用户清除Cookie的影响。
3、Session ID:为每个用户的会话分配一个唯一的Session ID,通过Session ID来追踪用户的行为。
网站反爬虫防护规则
网站为了保护自己的数据不被恶意爬虫抓取,通常会采取一系列的反爬虫措施,这些措施既可以是技术性的,也可以是法律性的。
技术性措施
1、Robots协议:通过robots.txt文件告知爬虫哪些页面可以抓取,哪些不可以。
2、验证码:使用图像验证码或短信验证码来验证访问者是否为真实用户。
3、访问频率限制:限制单个IP地址在一定时间内的访问次数。
4、动态页面生成:使用JavaScript或其他技术动态生成页面内容,增加爬虫抓取难度。
5、API防护:对API接口进行认证和加密,防止未经授权的访问。
法律性措施
1、服务条款:在网站的服务条款中明确禁止未经授权的数据抓取行为。
2、版权声明:通过版权声明保护网站内容的版权,警告潜在的侵权者。
防御爬虫攻击的策略
除了上述的反爬虫措施,网站还可以采取更主动的策略来防御爬虫攻击。
主动防御策略
1、行为分析:监控访问者的行为模式,识别出不符合正常用户行为的访问。
2、爬虫识别系统:使用机器学习等技术自动识别爬虫并进行拦截。
3、蜜罐技术:设置陷阱页面吸引爬虫,一旦爬虫访问这些页面即可被识别并采取措施。
相关问答FAQs
Q1: 数据去重是否会降低爬虫的效率?
A1: 数据去重确实会增加爬虫的计算负担,因为它需要额外的步骤来检查数据的重复性,从长远来看,去重可以提高数据的质量,减少存储空间的浪费,并且避免在后续的数据分析中出现错误,虽然短期内可能会降低效率,但长期而言是值得的。
Q2: 如何平衡网站的开放性与反爬虫需求?
A2: 网站需要在提供开放数据和保护自身免受恶意爬虫攻击之间找到平衡点,可以通过合理的robots.txt配置和API设计来指导合法爬虫的使用;对于恶意爬虫,可以通过技术手段如验证码、访问频率限制等来进行防护,网站还可以通过法律手段来维护自己的权益,比如在服务条款中明确规定数据的使用规则。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/684073.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复